搜索到
19
篇与
的结果
-
 Java总结:JDBC连接操作数据库(一) 目录: 前言 一、JDBC结构 1.Java程序 2.JDBC管理器 3.驱动程序 4.数据库 二、JDBC编程的步骤 1、导入包 2、加载驱动程序 3、设置JDBC的连接地址信息 4、创建数据库连接 5、使用SQL语句操作数据库 5.1.Statement接口方法创建表: 5.2.PreparedStatement接口: 6、关闭连接 三、相关的类与方法 1、DriverManager类 ——管理驱动 2、Connection接口 ——建立连接 3、Statement接口 ——执行SQL语句 4、PreparedStatement接口 ——执行SQL语句 5、ResultSet接口 ——存放查询之后返回的结果 前言 Java Database Connectivity简称JDBC,属于Java核心API的一部分,是Java语言中用来规范客户端程序如何来访问数据库的应用程序接口。支持ANSI SQL-92标准,通过调用这些类和接口提供的成员方法,我们可以方便地连接各种不同的数据库,进而使用标准的SQL命令对数据库进行查询、插入、删除、更新等操作。 一、JDBC结构 1.Java程序 主要功能是根据JDBC方法实现对数据库的访问和操作。 主要任务有:请求与数据库建立连接,向数据库发送SQL请求,为结果集定义存储应用和数据类型,查询结果,处理错误,控制传输、提交及关闭连接等。 2.JDBC管理器 即驱动程序管理器,动态地管理和维护数据库查询查询所需要的所有驱动程序对象,实现Java程序与特定驱动程序的连接。 主要任务有:为特定数据库选择驱动程序,处理JDBC初始化调用,为每个驱动程序提供JDBC功能的入口,为JDBC调用执行参数等 3.驱动程序 主要任务:建立与数据库的连接,向数据库发送请求,用户程序请求是执行编译,将错误代码格式化成标准的JDBC错误代码。 编程所使用的数据库系统不同,所需要的驱动程序也有所不同。 4.数据库 按数据结构来存储和管理数据的计算机软件。 常见的数据库比如mysql、Oracle、SqlServer等。 二、JDBC编程的步骤 一次完整的JDBC实现过程分为以下几步: 1、导入包 在程序首部将相关的包导入程序 import java.sql.*; 2、加载驱动程序 使用Class.forName()方法来加载相应的驱动程序。不同数据库所需要加载的驱动程序也不同: // 加载mysql的驱动程序 Class.forName("com.mysql.jdbc.Driver"); //加载oracle的驱动程序 Class.forName("oracle.jdbc.driver.oracleDriver"); 3、设置JDBC的连接地址信息 指定JDBC要连接的地址、端口、数据库、用户名、密码等信息 String username = "root"; String password = "root"; String url = "jdbc:mysql://localhost:3306/test"; // 如果要往表中插入中文,还需要设置编码为utf-8 String url = "jdbc:mysql://localhost:3306/test?seUnicode=true&characterEncoding=utf8"; 其中,"jdbc:mysql"是连接协议,“localhost”是连接地址,“3306”是mysql的连接端口(mysql的默认连接端口是3306),“test”是要连接操作的数据库。 4、创建数据库连接 DriverManager 类中的getConnection() 方法用上一步设置好的url作为参数来创建一个连接对象,并返回这个连接对象给Connection的实例。 //url是上一步创建的连接地址 Connection conn = DriverManager.getConnection(url,username,password); 5、使用SQL语句操作数据库 JDBC中执行SQL语句可以使用Statement接口以及其子接口PreparedStatement接口,下面分别使用不同接口来举例简单说明其用法: 5.1.Statement接口方法创建表: /** * 例子:Statement接口执行创建表,并且插入一组数据 */ // 在当前数据库下创建一个学生表,表中包含主键字段id、姓名name、以及更新时间updatetime String sql1 = "create table student(id int NOT NULL AUTO_INCREMENT primary key,name char(10),updateTime Datetime)"; // 向创建的student表添加一组信息 String sql2 = "insert into student(name,updatetime) values('qwe',sysdate())"; // 创建一个Statement对象 Statement st = conn.createStatement(); // 用executeUpdate()函数执行不返回任何内容的sql语句,如INSERT、UPDATE、DELETE以及其他DDL(数据定义语言)等。其参数为SQL语句 // 执行建表SQL语句 st.executeUpdate(sql1); // execute()函数可以执行传进来的任意SQL语句 // 执行插入数据的SQL语句 st.execute(sql2); // 释放资源 st.close(); 5.2.PreparedStatement接口: /** * 例子:PreparedStatement接口执行查询表中数据的SQL语句 */ String sql3 = "select * from student"; // 创建一个PreparedStatement对象,同时对传入的SQL语句进行预编译 PreparedStatement ps = conn.prepareStatement(sql3); // PreparedStatement接口中的execute()方法是没有参数的,因为SQL语句在创建对象时已传入并且预编译了 ResultSet result = ps.executeQuery(); while(rs.next()){ // 通过索引来获取查询到的值 int id = rs.getInt(1); String name = rs.getString(2); // 通过列名来获取查询到的值 Date date = rs.getDate("updateTime"); } // 释放资源 ps.close(); 6、关闭连接 用完就要释放所连接的数据库及JDBC资源,关闭与数据库的连接 conn.close(); 上面就是是JDBC编程的基本流程,下面对这个过程中涉及到的一些类与方法做简单介绍: 三、相关的类与方法 1、DriverManager类 ——管理驱动 用于管理一组JDBC驱动程序的基本服务。 官方文档介绍:DriverManager (Java Platform SE 8 ) (langp.wang) 其常用成员方法如下: 返回值 方法体 说明 static Connection getConnection(String url) 用指定的数据库URL来创建连接 static Connection getConnection(String url, Properties info) 用指定的数据库URL和相关信息(用户名、用户密码等属性列表)来创建连接 static Connection getConnection(String url, String user, String password) 用指定的数据库URL、用户名和用户密码来创建连接 static Driver getDriver(String url) 定位在给定URL下的驱动程序。 DriverManager尝试从已注册的JDBC驱动程序集中选择适当的驱动程序。 static void deregisterDriver(Driver driver) 从DriverManager的已注册驱动程序列表中删除指定的驱动程序。 static void println(String message) 将消息输出到当前JDBC日志流。 static void setLoginTimeout(int seconds) 驱动程序尝试连接数据库时将等待的最长时间,以秒为单位。 2、Connection接口 ——建立连接 负责建立与指定数据库的连接。 默认情况下,Connection对象处于自动提交模式,这意味着它在执行每个语句后自动提交更改。 如果禁用了自动提交模式,则必须显式调用方法commit()方法才能提交更改;否则,将不会保存数据库更改。 官方文档介绍: Connection (Java Platform SE 8 ) (langp.wang) 其常用成员方法如下: 返回值 方法体 说明 Statement createStatement() 创建一个Statement对象,用于将SQL语句发送到数据库。 PreparedStatement prepareStatement(String sql) 创建一个PreparedStatement对象,用于将参数化的SQL语句发送到数据库。 void close() 立即释放此Connection对象的数据库和JDBC资源,而不是等待它们自动释放。 void commit() 使自上一次提交/回退以来进行的所有更改永久生效,并释放此Connection对象当前持有的所有数据库锁。 void rollback() 撤销对数据库执行的添加、删除或者修改记录等操作,并释放此Connection对象当前持有的所有数据库锁。 3、Statement接口 ——执行SQL语句 用于执行静态SQL语句并返回其产生的结果的对象。 默认情况下,每个Statement对象只能同时打开一个ResultSet对象。 因此,如果一个ResultSet对象的读取与另一个的读取交错,则每个都必须由不同的Statement对象生成。 如果当前存在打开的语句,Statement接口中的所有执行方法都会隐式关闭该语句的当前ResultSet对象。 官方文档介绍: Statement (Java Platform SE 8 ) (langp.wang) 其常用成员方法如下: 返回值 方法体 说明 Connection getConnection() 检索产生此Statement对象的Connection对象 void close() 立即释放此Statement对象的数据库和JDBC资源,而不是在自动关闭时等待它发生 boolean execute(String sql) 执行给定的SQL语句,该语句可能返回多个结果 ResultSet executeQuery(String sql) 执行给定的SQL语句,该语句返回一个ResultSet对象 int executeUpdate(String sql) 执行给定的SQL语句,该语句可以是INSERT,UPDATE或DELETE语句,也可以是不返回任何内容的SQL语句,例如SQL DDL语句 ResultSet getResultSet() 以ResultSet对象的形式检索当前结果 executeUpdate()、executeQuery()与execute()方法的区别: execute()函数:可以执行所有SQL语句。 当执行查询语句时,返回的boolean值指示查询结果的形式,返回值为true时表示查询结果为ResultSet,反之为false(即认为没有查到);执行其他语句时,如果第一个结果是更新计数或不存在任何结果,则返回false executeUpdate():执行insert、update、delete等不返回任何内容的非查询语句。 executeQuery():用于执行select语句。返回一个ResultSet对象,其中包含由给定查询产生的数据; 永不为空 4、PreparedStatement接口 ——执行SQL语句 表示预编译的SQL语句的对象。是Statement的子接口。 创建PreparedStatement对象时需传入一个SQL语句,该SQL语句已预编译并存储在PreparedStatement对象中。然后可以使用该对象多次有效地执行该语句。 官方文档介绍: PreparedStatement (Java Platform SE 8 ) (langp.wang) 其常用成员方法如下: 返回值 方法体 说明 boolean execute() 在此PreparedStatement对象中执行SQL语句,可以是任何类型的SQL语句 ResultSet executeQuery() 在此PreparedStatement对象中执行SQL查询,并返回查询生成的ResultSet对象 int executeUpdate() 在此PreparedStatement对象中执行SQL语句,该对象必须是SQL数据操作语言(DML)语句,例如INSERT,UPDATE或DELETE; 或不返回任何内容的SQL语句,例如DDL语句 5、ResultSet接口 ——存放查询之后返回的结果 表示数据库结果集的数据表,通常通过执行查询数据库的语句来生成。 ResultSet对象有一个游标,该游标指向其当前数据行。 最初,光标位于第一行之前。next()方法可将光标移动到下一行,当ResultSet对象中没有更多行时它将返回false,因此可以在while循环中使用它来迭代结果集。例如: // 假设rs是前面进行查询操作返回的ResultSet对象 while(rs.next()){ // 输出结果 } 用next()方法可以实现访问每一个数据行,那么如何获取数据行中的每一列数据呢?ResultSet接口提供了用于从当前行中检索列值的getter方法,方法名是get+类型,如getBoolean(),getInt()。 getter方法的参数可以是列的索引值或者列的名称,对应的是用索引或者列名来从当前数据行中检索列值。 通常,使用列索引会更有效。 列从1开始编号。为实现最大的可移植性,应按从左到右的顺序读取每一行中的结果集列,并且每一列只能读取一次。 getter方法用列名检索时传入的列名称不区分大小写。 当多个列具有相同的名称时,将返回第一个匹配列的值。 对于在查询中未明确命名的列,最好使用列的索引。 如果使用了列名,则应注意确保它们唯一地引用了预期的列,这可以通过SQL AS子句来确保。 例如: // 假设rs是前面进行查询操作返回的ResultSet对象 while(rs.next()){ // 使用索引来检索 int id = rs.getInt(1); // 使用列的名称来检索 String name = rs.getString("name"); // 且列名不区分大小写 Date updateTime = rs.getDate("UPDATETIME"); } 官方文档介绍: ResultSet (Java Platform SE 8 ) (langp.wang) 其常用成员方法如下: 返回值 方法体 说明 boolean absolute(int row) 将光标移动到此ResultSet对象中的给定行号 boolean first() 将光标移动到此ResultSet对象的第一行 void beforeFirst() 将光标移动到此ResultSet对象的前面,紧挨着第一行 boolean isFirst() 检索光标是否在此ResultSet对象的第一行上 boolean last() 将光标移动到此ResultSet对象的最后一行 void afterLast() 将光标移动到此ResultSet对象的末尾,紧接在最后一行之后 boolean isLast() 检索光标是否在此ResultSet对象的最后一行 boolean next() 将光标从当前位置向前移动一行 void insertRow() 将插入行的内容插入到此ResultSet对象和数据库中 void updateRow() 使用此ResultSet对象的当前行的新内容更新底层数据库 void deleteRow() 从此ResultSet对象和底层数据库中删除当前行 void update类型(int ColumnIndex,类型 x) 使用给定类型x更新指定列 int get类型(int ColumnIndex) 以Java类型的形式获取此ResultSet的对象的当前行中指定列的值 主要参考资料: 《数据库系统概论(第5版)》 王珊 萨师煊 编著 Java SE 1.8 官方文档
Java总结:JDBC连接操作数据库(一) 目录: 前言 一、JDBC结构 1.Java程序 2.JDBC管理器 3.驱动程序 4.数据库 二、JDBC编程的步骤 1、导入包 2、加载驱动程序 3、设置JDBC的连接地址信息 4、创建数据库连接 5、使用SQL语句操作数据库 5.1.Statement接口方法创建表: 5.2.PreparedStatement接口: 6、关闭连接 三、相关的类与方法 1、DriverManager类 ——管理驱动 2、Connection接口 ——建立连接 3、Statement接口 ——执行SQL语句 4、PreparedStatement接口 ——执行SQL语句 5、ResultSet接口 ——存放查询之后返回的结果 前言 Java Database Connectivity简称JDBC,属于Java核心API的一部分,是Java语言中用来规范客户端程序如何来访问数据库的应用程序接口。支持ANSI SQL-92标准,通过调用这些类和接口提供的成员方法,我们可以方便地连接各种不同的数据库,进而使用标准的SQL命令对数据库进行查询、插入、删除、更新等操作。 一、JDBC结构 1.Java程序 主要功能是根据JDBC方法实现对数据库的访问和操作。 主要任务有:请求与数据库建立连接,向数据库发送SQL请求,为结果集定义存储应用和数据类型,查询结果,处理错误,控制传输、提交及关闭连接等。 2.JDBC管理器 即驱动程序管理器,动态地管理和维护数据库查询查询所需要的所有驱动程序对象,实现Java程序与特定驱动程序的连接。 主要任务有:为特定数据库选择驱动程序,处理JDBC初始化调用,为每个驱动程序提供JDBC功能的入口,为JDBC调用执行参数等 3.驱动程序 主要任务:建立与数据库的连接,向数据库发送请求,用户程序请求是执行编译,将错误代码格式化成标准的JDBC错误代码。 编程所使用的数据库系统不同,所需要的驱动程序也有所不同。 4.数据库 按数据结构来存储和管理数据的计算机软件。 常见的数据库比如mysql、Oracle、SqlServer等。 二、JDBC编程的步骤 一次完整的JDBC实现过程分为以下几步: 1、导入包 在程序首部将相关的包导入程序 import java.sql.*; 2、加载驱动程序 使用Class.forName()方法来加载相应的驱动程序。不同数据库所需要加载的驱动程序也不同: // 加载mysql的驱动程序 Class.forName("com.mysql.jdbc.Driver"); //加载oracle的驱动程序 Class.forName("oracle.jdbc.driver.oracleDriver"); 3、设置JDBC的连接地址信息 指定JDBC要连接的地址、端口、数据库、用户名、密码等信息 String username = "root"; String password = "root"; String url = "jdbc:mysql://localhost:3306/test"; // 如果要往表中插入中文,还需要设置编码为utf-8 String url = "jdbc:mysql://localhost:3306/test?seUnicode=true&characterEncoding=utf8"; 其中,"jdbc:mysql"是连接协议,“localhost”是连接地址,“3306”是mysql的连接端口(mysql的默认连接端口是3306),“test”是要连接操作的数据库。 4、创建数据库连接 DriverManager 类中的getConnection() 方法用上一步设置好的url作为参数来创建一个连接对象,并返回这个连接对象给Connection的实例。 //url是上一步创建的连接地址 Connection conn = DriverManager.getConnection(url,username,password); 5、使用SQL语句操作数据库 JDBC中执行SQL语句可以使用Statement接口以及其子接口PreparedStatement接口,下面分别使用不同接口来举例简单说明其用法: 5.1.Statement接口方法创建表: /** * 例子:Statement接口执行创建表,并且插入一组数据 */ // 在当前数据库下创建一个学生表,表中包含主键字段id、姓名name、以及更新时间updatetime String sql1 = "create table student(id int NOT NULL AUTO_INCREMENT primary key,name char(10),updateTime Datetime)"; // 向创建的student表添加一组信息 String sql2 = "insert into student(name,updatetime) values('qwe',sysdate())"; // 创建一个Statement对象 Statement st = conn.createStatement(); // 用executeUpdate()函数执行不返回任何内容的sql语句,如INSERT、UPDATE、DELETE以及其他DDL(数据定义语言)等。其参数为SQL语句 // 执行建表SQL语句 st.executeUpdate(sql1); // execute()函数可以执行传进来的任意SQL语句 // 执行插入数据的SQL语句 st.execute(sql2); // 释放资源 st.close(); 5.2.PreparedStatement接口: /** * 例子:PreparedStatement接口执行查询表中数据的SQL语句 */ String sql3 = "select * from student"; // 创建一个PreparedStatement对象,同时对传入的SQL语句进行预编译 PreparedStatement ps = conn.prepareStatement(sql3); // PreparedStatement接口中的execute()方法是没有参数的,因为SQL语句在创建对象时已传入并且预编译了 ResultSet result = ps.executeQuery(); while(rs.next()){ // 通过索引来获取查询到的值 int id = rs.getInt(1); String name = rs.getString(2); // 通过列名来获取查询到的值 Date date = rs.getDate("updateTime"); } // 释放资源 ps.close(); 6、关闭连接 用完就要释放所连接的数据库及JDBC资源,关闭与数据库的连接 conn.close(); 上面就是是JDBC编程的基本流程,下面对这个过程中涉及到的一些类与方法做简单介绍: 三、相关的类与方法 1、DriverManager类 ——管理驱动 用于管理一组JDBC驱动程序的基本服务。 官方文档介绍:DriverManager (Java Platform SE 8 ) (langp.wang) 其常用成员方法如下: 返回值 方法体 说明 static Connection getConnection(String url) 用指定的数据库URL来创建连接 static Connection getConnection(String url, Properties info) 用指定的数据库URL和相关信息(用户名、用户密码等属性列表)来创建连接 static Connection getConnection(String url, String user, String password) 用指定的数据库URL、用户名和用户密码来创建连接 static Driver getDriver(String url) 定位在给定URL下的驱动程序。 DriverManager尝试从已注册的JDBC驱动程序集中选择适当的驱动程序。 static void deregisterDriver(Driver driver) 从DriverManager的已注册驱动程序列表中删除指定的驱动程序。 static void println(String message) 将消息输出到当前JDBC日志流。 static void setLoginTimeout(int seconds) 驱动程序尝试连接数据库时将等待的最长时间,以秒为单位。 2、Connection接口 ——建立连接 负责建立与指定数据库的连接。 默认情况下,Connection对象处于自动提交模式,这意味着它在执行每个语句后自动提交更改。 如果禁用了自动提交模式,则必须显式调用方法commit()方法才能提交更改;否则,将不会保存数据库更改。 官方文档介绍: Connection (Java Platform SE 8 ) (langp.wang) 其常用成员方法如下: 返回值 方法体 说明 Statement createStatement() 创建一个Statement对象,用于将SQL语句发送到数据库。 PreparedStatement prepareStatement(String sql) 创建一个PreparedStatement对象,用于将参数化的SQL语句发送到数据库。 void close() 立即释放此Connection对象的数据库和JDBC资源,而不是等待它们自动释放。 void commit() 使自上一次提交/回退以来进行的所有更改永久生效,并释放此Connection对象当前持有的所有数据库锁。 void rollback() 撤销对数据库执行的添加、删除或者修改记录等操作,并释放此Connection对象当前持有的所有数据库锁。 3、Statement接口 ——执行SQL语句 用于执行静态SQL语句并返回其产生的结果的对象。 默认情况下,每个Statement对象只能同时打开一个ResultSet对象。 因此,如果一个ResultSet对象的读取与另一个的读取交错,则每个都必须由不同的Statement对象生成。 如果当前存在打开的语句,Statement接口中的所有执行方法都会隐式关闭该语句的当前ResultSet对象。 官方文档介绍: Statement (Java Platform SE 8 ) (langp.wang) 其常用成员方法如下: 返回值 方法体 说明 Connection getConnection() 检索产生此Statement对象的Connection对象 void close() 立即释放此Statement对象的数据库和JDBC资源,而不是在自动关闭时等待它发生 boolean execute(String sql) 执行给定的SQL语句,该语句可能返回多个结果 ResultSet executeQuery(String sql) 执行给定的SQL语句,该语句返回一个ResultSet对象 int executeUpdate(String sql) 执行给定的SQL语句,该语句可以是INSERT,UPDATE或DELETE语句,也可以是不返回任何内容的SQL语句,例如SQL DDL语句 ResultSet getResultSet() 以ResultSet对象的形式检索当前结果 executeUpdate()、executeQuery()与execute()方法的区别: execute()函数:可以执行所有SQL语句。 当执行查询语句时,返回的boolean值指示查询结果的形式,返回值为true时表示查询结果为ResultSet,反之为false(即认为没有查到);执行其他语句时,如果第一个结果是更新计数或不存在任何结果,则返回false executeUpdate():执行insert、update、delete等不返回任何内容的非查询语句。 executeQuery():用于执行select语句。返回一个ResultSet对象,其中包含由给定查询产生的数据; 永不为空 4、PreparedStatement接口 ——执行SQL语句 表示预编译的SQL语句的对象。是Statement的子接口。 创建PreparedStatement对象时需传入一个SQL语句,该SQL语句已预编译并存储在PreparedStatement对象中。然后可以使用该对象多次有效地执行该语句。 官方文档介绍: PreparedStatement (Java Platform SE 8 ) (langp.wang) 其常用成员方法如下: 返回值 方法体 说明 boolean execute() 在此PreparedStatement对象中执行SQL语句,可以是任何类型的SQL语句 ResultSet executeQuery() 在此PreparedStatement对象中执行SQL查询,并返回查询生成的ResultSet对象 int executeUpdate() 在此PreparedStatement对象中执行SQL语句,该对象必须是SQL数据操作语言(DML)语句,例如INSERT,UPDATE或DELETE; 或不返回任何内容的SQL语句,例如DDL语句 5、ResultSet接口 ——存放查询之后返回的结果 表示数据库结果集的数据表,通常通过执行查询数据库的语句来生成。 ResultSet对象有一个游标,该游标指向其当前数据行。 最初,光标位于第一行之前。next()方法可将光标移动到下一行,当ResultSet对象中没有更多行时它将返回false,因此可以在while循环中使用它来迭代结果集。例如: // 假设rs是前面进行查询操作返回的ResultSet对象 while(rs.next()){ // 输出结果 } 用next()方法可以实现访问每一个数据行,那么如何获取数据行中的每一列数据呢?ResultSet接口提供了用于从当前行中检索列值的getter方法,方法名是get+类型,如getBoolean(),getInt()。 getter方法的参数可以是列的索引值或者列的名称,对应的是用索引或者列名来从当前数据行中检索列值。 通常,使用列索引会更有效。 列从1开始编号。为实现最大的可移植性,应按从左到右的顺序读取每一行中的结果集列,并且每一列只能读取一次。 getter方法用列名检索时传入的列名称不区分大小写。 当多个列具有相同的名称时,将返回第一个匹配列的值。 对于在查询中未明确命名的列,最好使用列的索引。 如果使用了列名,则应注意确保它们唯一地引用了预期的列,这可以通过SQL AS子句来确保。 例如: // 假设rs是前面进行查询操作返回的ResultSet对象 while(rs.next()){ // 使用索引来检索 int id = rs.getInt(1); // 使用列的名称来检索 String name = rs.getString("name"); // 且列名不区分大小写 Date updateTime = rs.getDate("UPDATETIME"); } 官方文档介绍: ResultSet (Java Platform SE 8 ) (langp.wang) 其常用成员方法如下: 返回值 方法体 说明 boolean absolute(int row) 将光标移动到此ResultSet对象中的给定行号 boolean first() 将光标移动到此ResultSet对象的第一行 void beforeFirst() 将光标移动到此ResultSet对象的前面,紧挨着第一行 boolean isFirst() 检索光标是否在此ResultSet对象的第一行上 boolean last() 将光标移动到此ResultSet对象的最后一行 void afterLast() 将光标移动到此ResultSet对象的末尾,紧接在最后一行之后 boolean isLast() 检索光标是否在此ResultSet对象的最后一行 boolean next() 将光标从当前位置向前移动一行 void insertRow() 将插入行的内容插入到此ResultSet对象和数据库中 void updateRow() 使用此ResultSet对象的当前行的新内容更新底层数据库 void deleteRow() 从此ResultSet对象和底层数据库中删除当前行 void update类型(int ColumnIndex,类型 x) 使用给定类型x更新指定列 int get类型(int ColumnIndex) 以Java类型的形式获取此ResultSet的对象的当前行中指定列的值 主要参考资料: 《数据库系统概论(第5版)》 王珊 萨师煊 编著 Java SE 1.8 官方文档 -
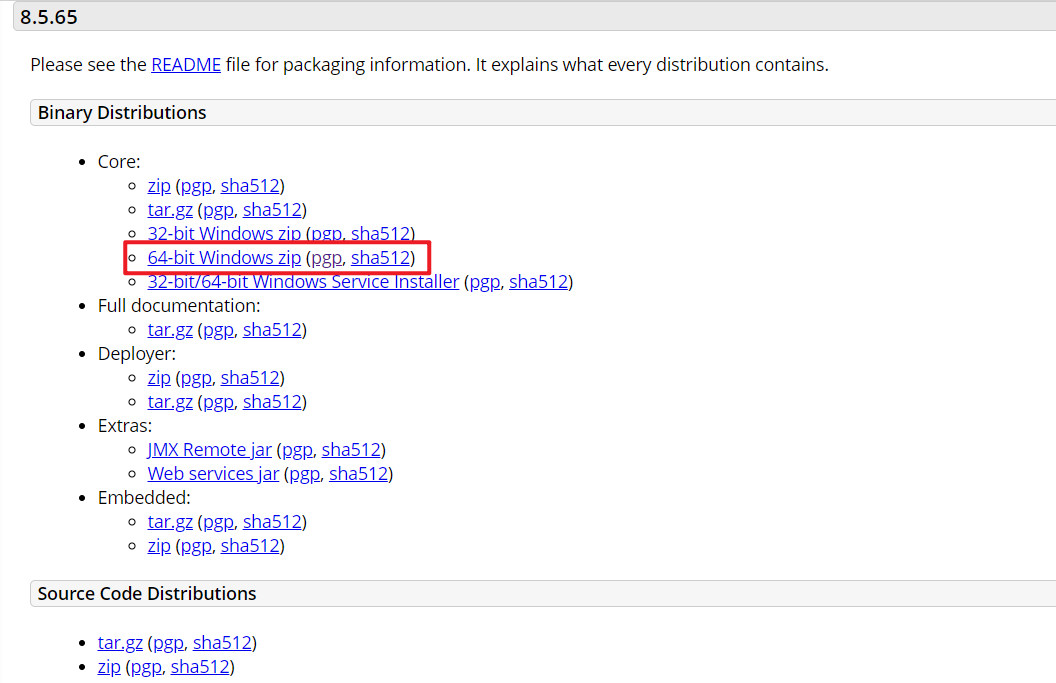
IDEA添加并配置Tomcat服务器 目录: 一、提前准备 二、创建Java web项目 三、添加Tomcat服务器 四、启动Tomcat服务器 五、其他操作 更改Tomcat默认端口 环境说明: 系统:Win10专业版 JDK版本:1.8 Tomcat版本:8.5.57 开发环境:IDEA 2020.03 Ultimate 一、提前准备 首先,访问Tomcat官网,选择一个版本的Tomcat进行下载,下载完之后解压。本篇博客以Tomcat8.5为例,下载的是windows 64位。下载完之后解压,记住解压完的文件位置,后面导入服务器时要用到。 其次,要保证当前的计算机正确配置了Java环境,win10系统下Java环境的配置请参考:Win10系统配置Java开发环境 二、创建Java web项目 注意:IDEA的Community版本是无法进行Web开发的,Web开发需要Ultimate版本 打开IDEA,先创建一个Java项目。然后在项目名上依次点击右键->”Add Framework Support“,弹出的窗口中勾选“Web Application”选项,点击右下角“OK”即可。 这样创建出来的就是Java web项目了,原来的项目目录会多出来一个“web”文件夹: 三、添加Tomcat服务器 依次点击“File”->“setting”(或者快捷键Ctrl+Alt+s)打开设置界面,然后选择“Build,Execution,Deployment”->“Application Servers”,点击“+”新添加一个应用服务器: 选择的服务器类型为“Tomcat Server”,注意不要选成“TomEE Server”: 在弹出的窗口中选择本地Tomcat的所在目录,IDEA会自动识别出Tomcat的版本,两连“OK”退出 回到主界面,找到菜单栏右边的“Add Configuration”: 点击左上角“+”,在展开的列表中依次选择“Tomcat Server”->“Local”,新建一个本地服务配置。因为前面添加了Tomcat服务器,所以右侧窗口中出现的配置项已自动填好,有需要的可以根据下图说明来改变部分选项: 然后我们需要把之前新建的这个项目放到Tomcat服务器上运行。切换到选项卡“Deployment”,点击左下角“+”,选择“Artifact”,当前项目就被添加上去了,添加完点击“OK”退出。 四、启动Tomcat服务器 如果前面配置没问题的话,现在左下角会出现“Services”窗口选项,在服务器名称上右键->“Run”,Tomcat服务器就启动了。 等待几秒钟服务器完全启动之后,会自动在浏览器中打开项目,如果没有自动打开那就用“localhost:8080”在浏览器中访问项目。 当前由于我们运行的只是空项目,没有对项目做任何更改,所以项目的运行结果会是下面这样: 到这里就配置成功了。 五、其他操作 更改Tomcat默认端口 在主界面找到菜单栏右边的“Tomcat ”,选择“Edit Configurations”: “HTTP port”是默认端口,更改完之后要重启Tomcat服务器才能生效 暂时这些,其他的碰到再添加。
-
Win10系统配置Java开发环境 目录: 两句废话 一、安装JDK 二、配置环境变量 三、验证环境是否搭建成功 环境说明: 系统:Win10专业版 Java版本:1.8 两句废话 最近收到了升级Win10 20H2版本的更新消息(别问我为什么2021年才收到2020年的更新包,问就是不知道),之前也听说这是修复Bug的一次更新。所以出于对微软的信任,原来的旧系统我并没有备份,就直接升级了系统,系统升级过程还算顺利。但是,我还是太”轻敌“了,新系统用了几天之后,原来的Bug修没修复还真没感觉出来,能感觉出来的反倒是是几个新的Bug:Win+V打不开剪贴板,运行窗口用notepad打不开记事本,快捷键Shift+Win+S无法打开windows自带的截图功能,这几项Bug暂且还能接受,因为有其他第三方软件能够代替这几个功能。最让我难受的一个Bug就是全屏开始菜单里的图标全成了光秃秃的小方块,没有应用名字,也没有图案logo,每次打开开始菜单都得回忆一下要找的应用的位置,非常麻烦,网上提供的方法也基本上都是治标不治本,用了一周多实在是忍受不了这些Bug,于是忍痛重装了系统。 所以话说回来,更新Win10之前一定要把原来的系统备份一遍!!!!这次经历可真是太长记性了。 重装完系统的确清爽多了,但是写Java时,才想起来新系统的Java环境还没配置,所以把配置Java环境的过程记录下来,方便以后查询(以后谁要让我帮他配Java环境,我就把这篇博客链接扔过去)。 嗯,废话讲完了。 附上Oracle官方文档中安装Java环境的相关链接:JDK Installation for Microsoft Windows (oracle.com) 一、安装JDK 首先下载JDK安装包。 Java 官网:Oracle 甲骨文中国 | 集成的云应用和平台服务 JDK 最新版本下载:Java Downloads | Oracle 旧版本 JDK 下载:Java Archive | Oracle 选择一个Java版本之后,选择“Windows x64”版本进行下载。 由于下载 JDK 旧版本需要登录 Oracle 帐号,随便用临时邮箱注册了一个账号,用这个就行: 帐号:linshi@linshiyouxiang.net 密码:Youxiang123@ 本篇博客以JDK 8(也称为JDK 1.8)作为示例来说明。 下载好之后打开安装,安装的是JDK和JRE两部分。安装时直接一路点击“下一步”,安装注意一下安装位置,后面要用。 二、配置环境变量 “计算机”图标上点击右键->属性->高级系统设置(win10 20H2需要在属性窗口的后面才能找到高级系统设置),在高级系统设置窗口的右下角点击“环境变量”。 “环境变量”分为两部分,一个是“用户变量”,这里面配置的环境变量只适用于当前计算机用户,另一个是“系统变量”,设置的环境变量适用于这台计算机上的所有用户。具体设置成哪种环境变量看个人习惯。 添加如下两条环境变量: 环境变量名称 环境变量值 JAVA_HOME C:\Program Files\Java\jdk1.8.0_221 Path %JAVA_HOME%\bin JAVA_HOME的值是JDK的安装路径,如果在上一步安装的时候没有更改安装路径的话,则JDK的默认安装路径为:“C:\Program Files\Java\jdk1.8.0_221 ”,因为版本号的问题,JDK的安装文件夹名称可能会有些许差别,请根据实际情况写。 其实第一个环境变量的名称并不是固定的,在其他的配置Java环境变量的教程中名称也可能不同。这个只是习惯而已,只要保证环境变量值没什么问题即可。 这两条添加完之后,两连“确定”完成配置。 三、验证环境是否搭建成功 使用快捷键Win+R打开运行窗口,输入“cmd”,然后回车打开命令行界面,使用如下命令查看当前系统的Java版本: java -version 结果如下: 结果正确显示出Java的版本信息时,说明Java环境配置成功。
-
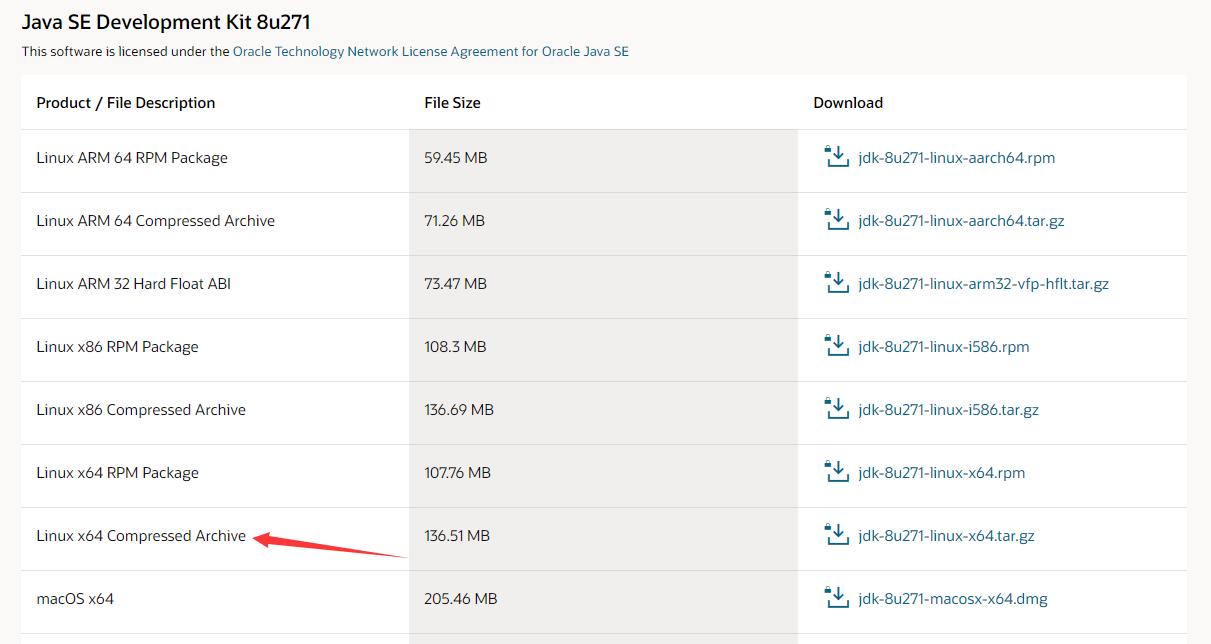
在ubuntu系统下配置Java环境 目录: 1. 从Java官网下载JDK安装包 2.解压Java安装包 3. 配置环境变量 4. 检验是否配置完成 环境说明: 操作系统:Ubuntu 18.0.4 server JDK版本:JDK 8 1. 从Java官网下载JDK安装包 Java官网:Oracle 甲骨文中国 | 集成的云应用和平台服务 JDK最新版本下载:Java Downloads | Oracle 其他版本JDK 下载:Java Archive | Oracle 本教程以 JDK 8(也称为JDK 1.8)作为示例。 由于下载JDK旧版本需要登录Oracle帐号,随便用临时邮箱注册了一个账号,用这个就行: 帐号:linshi@linshiyouxiang.net 密码:Youxiang123@ 下载时,选择下载压缩包: 2.解压Java安装包 将下载好的安装包上传到Linux环境上,然后解压安装包。解压在哪都可以,这里以/usr为例,先进入/usr目录: cd /usr 找到刚才下载的Java安装文件,解压到当前目录: # 我下载的jdk的路径是/home/wlp/Downloads/jdk-8u271-linux-x64.tar.gz: sudo tar -zxvf /home/wlp/Downloads/jdk-8u271-linux-x64.tar.gz 解压完之后使用ls -a命令查看解压完的的文件夹名称,为jdk1.8.0_271(你的大版本或者小版本可能跟我的不同,文件名也不会相同,不能照抄),为方便配置,将解压后的文件夹名修改为jdk1.8: sudo mv jdk1.8.0_271 jdk1.8 3. 配置环境变量 编辑 /etc/profile: sudo nano /etc/profile 在打开的文件最后加入如下环境变量设置: export JAVA_HOME=/usr/jdk1.8 export JRE_HOME=${JAVA_HOME}/jre export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib export PATH=${JAVA_HOME}/bin:$PATH 注意:第一句中的 JDK 路径不能照抄,请务必保证这个路径是你刚解压的 JDK 的绝对路径 更改完成后,ctrl + o保存,ctrl + x退出,回到终端界面。执行如下命令使环境变量生效: source /etc/profile 4. 检验是否配置完成 在命令行中输入java -version,查看安装的java版本,如果没问题的话,结果如下: java version "1.8.0_271" Java(TM) SE Runtime Environment (build 1.8.0_271-b12) Java HotSpot(TM) 64-Bit Server VM (build 25.271-b12, mixed mode) 当出现的版本号与刚才安装的版本相同,说明Java环境配置成功。