

搜索到
52
篇与
的结果
-
 【踩坑实录】mybatis项目报错:Establishing SSL connection without...property is set to false 环境说明: 系统:Win10专业版 mysql 5.7 问题再现 操作数据库时,警告信息如下: WARN: Establishing SSL connection without server's identity verification is not recommended. According to MySQL 5.5.45+, 5.6.26+ and 5.7.6+ requirements SSL connection must be established by default if explicit option isn't set. For compliance with existing applications not using SSL the verifyServerCertificate property is set to 'false'. You need either to explicitly disable SSL by setting useSSL=false, or set useSSL=true and provide truststore for server certificate verification. 以上警告信息翻译一下就是: 警告:不建议在没有服务器身份验证的情况下建立 SSL 连接。 根据MySQL 5.5.45+、5.6.26+ 和 5.7.6+ 要求,如果未设置显式选项,则必须默认建立 SSL 连接。 为了符合不使用 SSL 的现有应用程序,verifyServerCertificate 属性设置为“false”。您需要通过设置 useSSL=false 来显式禁用 SSL,或者设置 useSSL=true 并为服务器证书验证提供信任库。 解决方法 最省事的方法是修改数据库连接信息,在链接之后加上“useSSL=false”,直接禁用SSL连接方式。 原来链接为: jdbc:mysql://localhost:3306/mybatis?setUnicode=true&characterEncoding=utf8 加上参数之后修改为: jdbc:mysql://localhost:3306/mybatis?setUnicode=true&characterEncoding=utf8&useSSL=false 如果将参数设置为“useSSL=true”,在IDEA数据库连接界面设置SSL证书,也可以消除警告:
【踩坑实录】mybatis项目报错:Establishing SSL connection without...property is set to false 环境说明: 系统:Win10专业版 mysql 5.7 问题再现 操作数据库时,警告信息如下: WARN: Establishing SSL connection without server's identity verification is not recommended. According to MySQL 5.5.45+, 5.6.26+ and 5.7.6+ requirements SSL connection must be established by default if explicit option isn't set. For compliance with existing applications not using SSL the verifyServerCertificate property is set to 'false'. You need either to explicitly disable SSL by setting useSSL=false, or set useSSL=true and provide truststore for server certificate verification. 以上警告信息翻译一下就是: 警告:不建议在没有服务器身份验证的情况下建立 SSL 连接。 根据MySQL 5.5.45+、5.6.26+ 和 5.7.6+ 要求,如果未设置显式选项,则必须默认建立 SSL 连接。 为了符合不使用 SSL 的现有应用程序,verifyServerCertificate 属性设置为“false”。您需要通过设置 useSSL=false 来显式禁用 SSL,或者设置 useSSL=true 并为服务器证书验证提供信任库。 解决方法 最省事的方法是修改数据库连接信息,在链接之后加上“useSSL=false”,直接禁用SSL连接方式。 原来链接为: jdbc:mysql://localhost:3306/mybatis?setUnicode=true&characterEncoding=utf8 加上参数之后修改为: jdbc:mysql://localhost:3306/mybatis?setUnicode=true&characterEncoding=utf8&useSSL=false 如果将参数设置为“useSSL=true”,在IDEA数据库连接界面设置SSL证书,也可以消除警告: -
目前最流行的版本控制软件:Git的基本使用 前排提示: 本篇博客篇幅较长,建议结合目录查看! 目录: 写在前面 1、关于版本控制系统 定义 版本控制的必要性: 常见的版本控制系统 2、Git与Github 0x01.安装Git 0x02.Github中的一些基本概念 Repository Issue Star Fork Pull Request Watch Wiki Gist 0x03.添加SSH key 0x04.克隆仓库 0x05.初始化仓库 0x06.提交修改 0x07.分支操作 查看分支 建立新分支 切换分支 建立并切换到新分支 推送本地分支到远程仓库 合并分支 删除分支 重命名分支 0x08.标签操作 附注标签 轻量标签 切换标签 推送标签 删除标签 查看所有标签 给提交打标签 写在前面 1、关于版本控制系统 定义 版本控制(Version control)是维护项目的标准作法,能追踪项目从诞生一直到定案的过程。此外,版本控制也是一种软件工程技巧,借此能在软件开发的过程中,确保由不同人所编辑的同一程序文件都得到同步,记录项目内各个模块的改动历程,并为每次改动都编上序号。 一种简单的版本控制形式如下:工程的初代版本为“1.0”,当做了第一次改变后,版本等级改为“1.1”,以此类推。因此,版本控制能提供给开发者将项目恢复到之前任一状态的选择权,这种选择权在设计过程进入死胡同时特别重要。 版本控制的必要性: 常会利用版本控制来追踪维护源代码、文件以及配置文件等的改动,并且提供控制这些改动控制权的程序; 有时候,一个程序同时存有两个以上的版本,例如:在一个稳定版本中程序错误已经被修正、但没有加入新功能;在另一个开发版本则有新的功能正在开发、也有新的错误待解决,这使得同时间需要不同的版本; 此外,为了找出只存在于某一特定版本中(由于修正了某些问题、或新加功能所导致)的程序错误,或找出程序错误出现的版本,开发者也需要比对不同版本的代码以找出问题的位置。 常见的版本控制系统 集中式版本控制系统:由一台或多台主计算机组成中心服务器,所有业务单元和项目版本库都集中存储在这个中心服务器上,开发时,要先从中央服务器取得项目最新的版本,一次开发完毕之后,再将工作量推送给中央服务器。就像是一个图书馆,如果要改一本书的内容,则需要把书先从图书馆借出来,然后修改,改完之后再放回图书馆。 因此,集中式版本控制系统最的大缺点就是中央服务器出了问题,所有人都没法工作了。 常见的集中式版本控制系统有SVN、CVS等。 分布式版本控制系统:分布式版本系统没有绝对的中央服务器,每个人的电脑上都是一个完整的版本库,多个人进行协同工作时,只需将自己的修改与其他人的修改进行交换即可 和集中式版本控制系统相比,分布式版本控制系统的安全性要高很多,因为每个人电脑里都有完整的版本库,其中一个人的电脑坏了不要紧,从其他人那里复制一个就可以了。 Git就是常见的分布式版本控制系统之一,也是目前最流行的版本控制系统。 2、Git与Github 准确地说,Git与Github根本不是同一个概念。 Git是指由Linus(就是那位二十多年前徒手撸出Linux内核的大佬)编写的分布式版本控制系统,于2005年以GPL发布。最初目的是为了更好地管理Linux内核开发。 自2002年以来,Linus一直使用BitKeeper作为Linux内核主要的版本控制系统以维护代码。在Linux社区中,主张应该使用开放源代码的软件来作为Linux内核的版本控制系统。Linus曾考虑过采用现成软件作为版本控制系统(例如Monotone),但这些软件都存在一些问题,特别是性能不佳。 2005年,Linux社区中的安德鲁·垂鸠写了一个可以连接BitKeeper的存储库的简单程序,BitKeeper著作权拥有者拉里·麦沃伊便认为安德鲁·垂鸠对BitKeeper内部使用的协议进行了逆向工程,决定收回无偿使用BitKeeper的许可。Linux内核开发团队与BitMover公司进行磋商无果后,Linus决定自行开发版本控制系统以替代BitKeeper,在十天的时间编写出git第一个版本。于是,世界上最流行的版本控制系统就这么戏剧式地诞生了。 而GitHub是通过Git进行版本控制的软件源代码托管服务平台,由GitHub公司(曾称Logical Awesome)的开发者Chris Wanstrath、P. J. Hyett和Thomas Preston-Werner使用Ruby on Rails编写而成,于2007年10月1日开始开发。beta版本开始上线于2008年2月,4月份正式上线。这是他们的logo,名字叫Octocat: 截止到2020年1月,GitHub已经有超过4000万注册用户和1.9亿代码库(包括至少2800万开源代码库),事实上已经成为了世界上最大的代码存放网站和开源社区,国内很多人戏称为“全球最大同性交友网站”。 2018年6月4日晚,微软宣布以75亿美元的股票收购GitHub。 Github服务器在国外,处于半被墙的状态,有时正常访问,有时又打不开。与之类似的代码托管平台Gitee可以看做是国内版的Github,缺点是开源项目不如Github丰富,当然,由于在访问时速度更快,更适合国内用户托管代码。而且,部分开源项目是同时托管在这两个平台上的,所以碰到无法打开的Github项目时,在Gitee上找找也许会有惊喜。 0x01.安装Git Git在全平台均可使用。 Git官网:Git (git-scm.com) 官方中文文档:Git - Book (git-scm.com) Windows系统Git安装包下载链接:Git - Downloads Linux系统安装Git:Git - Download for Linux and Unix Mac系统安装Git:Git - Download for macOS 安装完成之后在控制台中输入git,如果出现如下输出说明安装成功: 前面提到过,Git只是一个分布式版本管理软件,每个人的计算机都是一份完整的版本库,对这份版本库进行修改之后,将每个人的修改进行合并。但是如果不在同一个内网中,合并修改就会变得困难。此时也需要一个中央服务器来辅助进行代码的合并。这也就是Github、Gitee、Gitlab等平台最基本的作用。 因此,我们还需要注册一个Github/Gitee账号,将我们的代码托管到平台上面(从某种角度上将它看成一个专门存放代码的云盘也未尝不可)。Github注册账号及用户界面介绍可以参考这篇文章:从0开始学习 GitHub 系列之「加入 GitHub」 (qq.com),本篇博客不再介绍。 0x02.Github中的一些基本概念 Repository 仓库,即项目,要在GitHub上开源一个项目,那就必须要新建一个Repository。 Issue 问题的意思,举个例子,比如开源的项目,别人发现项目中有bug,或者哪些地方做的不够好,他就可以提个Issue,即问题,提的问题多了,也就是 Issues ,然后开发者看到了这些问题就可以去逐个修复,修复ok了就可以一个个的Close掉。 Star 就是给项目点赞,这个star的含金量还是挺高的。 Fork 这个可以翻译成分叉,你想在某个开源项目的基础上做些改进,然后应用到自己的项目中,这个时候就可以Fork这个项目,与此同时你的GitHub主页上就多了一个项目,只不过这个项目是基于这个开源项目(本质上是在原有项目的基础上新建了一个分支)。而你就可以随心所欲的去改进这个项目了,丝毫不会影响原有项目的代码与结构。 Pull Request 发起请求,这个其实是基于Fork的,还是上面那个例子,如果你在项目基础上做了改进,就可以把自己的改进合并到原有项目里,这个时候你就可以发起一个Pull Request(简称PR),原有项目开发者会收到这个请求,这个时候他会review代码,并且测试觉得OK了,就会接受PR,这个时候新的改进会被合并进原有项目。 Watch 可以理解为观察,如果Watch了某个项目,以后如果这个项目有更新,都会收到关于这个项目的通知提醒。 Wiki 一般来说,项目的主页有README文件基本就够了,但是有些时候项目的一些用法很复杂,就需要有详细的说明文档给使用者。这个时候就可以用Wiki,使用markdown语法即可进行编写。 Gist 如果没有项目可以开源,只是单纯的想分享一些代码片段,那这个时候Gist就派上用场了。 0x03.添加SSH key 当我们对代码进行提交时,Github/Gitee要怎么知道是我们提交的代码,而不是别人提交的呢,所以就需要进行授权来确认我们的身份。 Github和Gitee服务器可以选择使用SSH公钥或GPG公钥来进行授权,这里采用SSH授权方式,提交代码之前需要先添加SSH key配置。大概步骤就是先在本地生成SSH key,然后将本地生成的SSH key添加到Github或者Gitee上。 SSH(Secure Shell)是一种建立在应用层基础上的安全协议,一般用于远程登录会话和其他网络服务。由于在传输过程中对数据进行了加密和压缩,因此可以有效防止远程管理过程中的“中间人攻击”,传输速度也会更快,还能够防止”DNS欺骗“和”IP欺骗“等。 生成SSH密钥: ssh-keygen -t rsa 这句命令的意思是用RSA算法生成密钥(windows系统最好在Git Bash下执行,cmd终端可能并没有安装ssh),执行后出来三次提示均按回车,命令执行完会生成id_rsa(密钥)和id_rsa.pub(公钥)这两个文件。Linux/Mac系统在~/.ssh下,windows系统在C:\Users\用户名\.ssh(用户名是自己电脑的用户名)下,需要设置显示隐藏文件选项才能看到。 将id_rsa.pub用文本编辑器打开,复制里面的内容。 添加公钥到Github/Gitee: 进入Github/Gitee的设置界面,在左侧选项列表找到SSH keys选项 将刚才复制的公钥粘贴上去,公钥标题可写可不写,然后保存,这样就完成了公钥的添加。 0x04.克隆仓库 说来惭愧,这是我接触到Github之后很长时间内最常用的操作(因为就只会这一个操作)。命令很简单: git clone [仓库链接] 这个命令的作用就是从Github上下载别人仓库的项目文件,可能是从clone直接音译过来的原因,这个操作一般都称克隆,而不叫下载。 克隆操作只需要有远程仓库链接即可,不需要Github账户也可以进行。克隆完之后项目文件的位置就是执行命令时所处的文件夹。 远程仓库链接在项目主页就可以找到: 0x05.初始化仓库 所谓初始化本地仓库,个人理解就是向本地的项目根目录文件夹中加入一些Git配置文件,使其可以被Git识别以进行版本控制,因为项目文件夹是不能直接进行版本控制的。 初始化本地仓库命令很简单,进入本地项目文件夹(或者用空文件夹),在该目录下执行: git init 也可以在命令后面加入文件夹路径,将指定文件夹初始化成本地仓库: git init [项目文件夹名路径] 项目初始化成功会有Initialized empty Git repository in xxxxxxx的提示,原项目文件夹中多出一个.git隐藏文件夹。此时初始化的本地项目还没有关联到远程仓库。 当然,有本地仓库还不行,我们本意是要把本地仓库推送到远程仓库,因此,还需要在Github/Gitee上建一个远程仓库。点击网站右上角加号,找到“New Repository(新建仓库)” 上图最后三项是用来初始化远程仓库的,如果这三项都不选就创建了仓库,就会提示用命令行来手动初始化远程仓库(所以建议对命令行不感冒的同学直接使用自带的初始化操作)。 来记录一下用命令行手动初始化远程仓库的步骤: 先在本地初始化好的Git项目中新建一个README.md项目说明文件(也可以是别的文件名) 在项目目录下执行命令与远程仓库进行关联: git remote add origin [远程仓库链接] 依次执行以下命令向暂存区加入修改文件,并编辑提交信息 git add README.md # 引号中就是本次提交信息,可修改 git commit -m "first commit" 向远程仓库推送本地仓库文件: Gitee只执行这条命令即可推送: git push -u origin master 从2020年10月开始,Github的默认分支从master变成了main,因此还需要将本地默认主分支重命名为main才能推送成功: git branch -M main git push -u origin main 如果不重命名主分支,就会出现“error: src refspec main does not match any,error: failed to push some refs to ..”的错误。 上述命令执行完之后,再刷新远程仓库界面,就进入了初始化好的远程仓库: 对于都已经初始化过的本地空仓库与远程仓库,使其建立关联可以这样做: # 先关联远程仓库 git remote add origin [仓库远程链接] # 再将远程仓库内容拉取到本地 git pull origin master 0x06.提交修改 所谓修改,就是相对于上次提交之后项目发生的改变(项目文件的增、删、改)。 其中要涉及到push和pull这两个互为相反的概念: Push:直译就是“推”的意思,这个操作可以把本地代码推到远程仓库,这样本地仓库跟远程仓库就可以保持同步了。 Pull:直译为“拉”的意思,如果别人提交代码到远程仓库,这个时候本地仓库代码与远程仓库代码并不一致,所以需要把远程仓库的最新代码拉下来,以保证两端代码的同步。 同时,提交代码前最好设置一下提交者的名字与邮箱,方便在commit记录里显示: git config —global user.name "名字" git config —global user.email "邮箱" 通常一次完整的提交过程如下: 将修改过的文件加入暂存区: git add [修改的文件或者目录] # .表示此目录下所有文件,一次提交的文件较多时,可以使用此命令 git add . 确认提交暂存区中的文件: # -m表示附加提交信息,后面的内容是关于提交的信息说明 git commit -m "提交信息" git add是先把改动添加到一个“暂存区”,可以理解成是一个缓存区域,临时保存改动,而git commit才是最后真正的提交。这样做的好处是防止误提交。 最后将代码推送到远程仓库指定分支,即可完成一次代码提(其中注意,最后提交时Gitee与Github的分支名有所不同): # 推送代码到指定分支 git push origin [分支名] # Github默认分支是main,用以下命令: git push origin main # Gitee默认分支是master,用以下命令: git push origin master 这里的origin是给远程仓库起的名字,当然名字并不唯一,可以是其他名字,只是因为习惯,一般都起名为origin。 一般在多人协作时,为了不产生代码冲突,提交代码前最好进行一次Pull操作: git pull origin [分支名] 查看git仓库当前状态,比如当前所在分支、被修改过的文件、未提交的文件等等: git status 查看提交时产生的所有commit记录: git log 0x07.分支操作 branch即分支的意思,分支的概念在团队协作的时候很重要,假设两个人都在做同一 个项目,这个时候分支就是保证两人能协同合作的最大利器了。举个例子,A, B两人在做同一个项目不同的模块,这个时候A新建了一个分支叫a,B新建了一个分支叫b,这样 A、B做的所有代码改动都在各自的分支上,互不影响,等到都把各自的模块做完 了,最后再统一把分支合并到master主分支。 在本地执行git init命令初始化仓库时默认生成一个主分支master。 而远程仓库的情况就有所不同了,曾经Github远程仓库的默认主分支也是master,但是去年(2020)10月份之后Github将默认主分支名称从master改成了main(据说是因为master这个词意为奴隶的主人,含有种族歧视意味),这也是在前面手动初始化Github仓库时要将主分支名重命名为main的原因。 而Gitee的主分支名称依然是master。 查看分支 查看本地分支列表: git branch 查看远程分支列表: git branch -r 建立新分支 git branch [分支名] 需要注意的是,新创建的分支的内容与当前所在的分支的内容相同,即新分支是基于当前所在的分支而创建的。 当我们建立了新分支以后,默认不会切换到新分支上,当前做出的任何更改还是基于当前所在的分支,所以需要切换分支。 切换分支 git checkout [分支名] # 切换到新分支之后手动拉取最新内容 git pull origin [分支名] 此时进行的改动就是在新分支下面了。当然,也有办法一步到位,加入-b参数即可。 建立并切换到新分支 git checkout -b [分支名] 推送本地分支到远程仓库 在本地建完新分支之后,就可以将本地新分支推送到远程仓库了,以保证两端同步 git push origin [新分支名] 如果本地推送到远程的分支想取另一个名字,那么可以用这条命令: git push origin [本地分支名]:[远程新分支名] 但是强烈不建议这样,这会导致管理混乱,建议本地分支跟远程分支名要保持 一致。 合并分支 当团队中不同成员都完成了开发之后,就可以将改动都合并到一块了。 # 首先切换到要合并到的分支上来,比如master(main)分支或是指定分支 git checkout [分支名]/main/master # 进行合并,将指定分支合并到当前所在的分支(即上一步切换到的分支)上来 git merge [指定分支] 在没有冲突的情况下,代码就可以合并完成了。合并完记得把新代码push到远程仓库。 删除分支 分支建错或者该分支的代码已经顺利合并到其他分支的时候,就可以删除分支了: git branch -d [分支名] 有些时候可能会删除失败,比如该分支的代码还没有合并到master或者其他分支,执行删除分支操作就会失败,Git会提示这个分支上还有未合并的代码,但是也可以强制删除分支: git branch -D [分支名] 以上仅仅为删除本地分支,若要删除远程分支可以可以运行带有 --delete 选项的 git push 命令: git push origin --delete [远程分支名] 重命名分支 将A分支重命名为B分支: git branch -m A B 类似于删除分支,无法重命名时,也可以强制重命名: git branch -M A B 如果是重命名远程分支,推荐的做法是: 删除远程待修改分支 push本地新分支名到远程 0x08.标签操作 开发的时候经常有版本的概念,比如v1.0、v1.1之类的,不同的版本肯定对应不同的代码,所以给代码打上标签,标签名可以是版本号或者其它标记。 Git 支持两种标签:附注标签(annotated)与轻量标签(lightweight)。 附注标签 附注标签是存储在Git数据库中的一个完整对象, 它们是可以被校验的,其中包含打标签者的名字、邮件地址、日期时间, 此外还有一个标签信息,并且可以使用GNU Privacy Guard(GPG)签名并验证。 通常建议创建附注标签,这样就可以拥有以上所有信息 添加附注标签信息用这条命令: git tag -a [标签名] -m "标签信息" -m参数为可选的,表示指定一条存储在标签中的信息。如果省略-m参数,那么Git会自动打开编辑器,让我们写一句标签信息,就像给提交写注解一样。 利用git show命令可以查看标签信息与对应的提交信息: git show [标签名] 输出会显示打标签者的信息、打标签的日期时间、附注信息与具体的提交信息。 轻量标签 如果只是想用一个临时的标签, 或者因为某些原因不想要保存这些信息,那么就可以用轻量标签。 轻量标签很像一个不会改变的分支——它只是某个特定提交的引用。本质上是将提交校验和存储到一个文件中——没有保存任何其他信息。 创建轻量标签,不需要使用 -a、-s 或 -m 选项,只需要提供标签名: git tag [标签名] 同样的,利用git show命令查看标签信息与对应的提交信息,输出只会显示出提交信息,不会看到额外的标签信息。 切换标签 当要切换到某个tag时,命令与切换分支类似: git checkout [标签名]; 推送标签 同样的,向远程仓库推送单个标签的命令与推送分支也是类似的: git push origin [标签名] 如果一次推送多个标签,可以使用带有--tags的git push命令: git push origin --tags 这条命令会将所有不在远程仓库服务器上的标签全部推送到远程仓库。 删除标签 删除本地标签: git tag -d [标签名] 上述命令并不会从远程仓库中移除这个标签,从远程仓库移除标签有两种办法: git push <remote> :[标签名称] 这种操作的含义是,将冒号前面的空值推送到远程标签名,从而实现删除的效果。 第二种方式相对来说更直观: git push origin --delete [标签名] 查看所有标签 执行git tag命令,就可以列出所有标签: git tag 默认是以字母顺序排列标签。 当然,可带上可选的 -l 选项或者 --list选项,以匹配特定标签名: git tag -l "通配符" # 或者 git tag --list "通配符" 例如,只查阅v2.*版本的标签名: git tag -l "v2.*" 给提交打标签 假设在过去某一个时刻提交了项目更改,后期才想起来忘记给项目打标签了,那么也可以在之后补上标签: git tag -a [标签名] [校验和] 与创建标签命令不同,需要在标签名之后添加一个校验和选项(也可以是部分校验和)。 通过以下命令可以查看每一次提交的校验和与对应的提交信息: git log --pretty=oneline 参考资料: 微信公众号 - stormzhang:从0开始学习Github系列文章 Git 教程 | 菜鸟教程 (runoob.com) Git - Book (git-scm.com) 版本控制 - 维基百科,自由的百科全书 (wikipedia.org) git - 维基百科,自由的百科全书 (wikipedia.org) GitHub - 维基百科,自由的百科全书 (wikipedia.org)
-
Linux设置定时任务:cron的用法 目录: 0x01.cron是什么 0x02.crontab命令语法 0x03.crontab任务规则 1、标准规则 2、非标准规则 0x04.其他 1、定时任务生效时间 2、定时任务不生效 3、环境变量相关问题 0x01.cron是什么 cron该词来源于希腊语chronos(χρόνος),原意是时间。是一款类Unix的操作系统下的基于时间的任务管理工具。用户可以通过cron在固定时间、间隔下,运行指定任务(可以是命令和脚本)。 cron的操作由crontab(cron 表)文件驱动,该文件是一个配置文件,用于指定按给定计划定期运行的shell命令。crontab文件存储在保存作业列表和cron守护程序的其他指令的位置。 用户可以拥有自己的个人crontab文件,并且通常有一个系统范围的crontab文件(通常在/etc或/etc的子目录中),只有系统管理员才能编辑。 要新添加一个定时任务,需要编辑crontab文件(即cron表),在其中添加相关任务即可,定时任务的编写规则见第三条。 0x02.crontab命令语法 crontab [ -u user ] { -l | -r | -e } 说明: -u user参数可以设定某一个用户的cron表,前提是必须要有相关权限(比如root权限),才能够设定其他人的crontab文件。如果不使用-u user的话,就是表示设定自己的crontab文件 -e:执行文字编辑器来设定时程表,内定的文字编辑器是vi -r:删除目前的cron表中的所有任务 -l:列出目前cron表中的所有任务 综上,简单总结基本的常用命令: 直接编辑crontab文件: crontab # 这个命令执行完之后,直接接受控制台中的输入流作为任务命令 用编辑器编辑crontab文件: crontab -e 删除当前所有的任务规则: crontab -r 列出目前所有的定时任务: crontab -l 其中,可以在crontab之后加上-u user的参数来操作指定用户对应的crontab文件,前提是必须要有相关权限(比如root权限)。否则就是操作自己的crontab文件。 0x03.crontab任务规则 1、标准规则 简单理解就是执行时间+ 命令的形式。 其中时间是由五个域组成,分别为分钟、小时、天、月份、星期,每个域可以放置单一或多个数值,同时每个域之间都有空格来进行区分,如下所示: ┌──────────── 分钟 (0 - 59) │ ┌──────────── 小时 (0 - 23) │ │ ┌──────────── 天 (1 - 31) │ │ │ ┌──────────── 月份 (1 - 12) │ │ │ │ ┌──────────── 星期中的某天 (0 - 6) (从周日开始算到周六) │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ * * * * * [用户名] <要执行的命令> 在用户层次的crontab文件中,用户名是可以省略的参数,而系统层次的crontabs文件的任务经常会指定一个或以上的用户进行执行,因此需要增加用户名字段。 注: 在某些系统里,星期日也可以为7 不很直观的用法:如果日期和星期同时被设定,那么当其中的一个条件被满足时,指令便会被执行。而不是同时满足 为方便个人记忆,前5个域可称之为分时日月周 表示时间的每个域里除了可以是具体数值,还可以是表达式或者是多个数值: 逗号(,)列举出多个数值,例如:1,3,4,7 * * * * echo hello world表示在每小时的1、3、4、7分时,打印"hello world"。 连词符(-)表示一个数值范围,例如:1-6 * * * * echo hello world ,表示每小时的1到6分钟内,每分钟都会打印"hello world"。 星号(*)代表任何可能的值。例如:在“小时域”里的星号等同于“每一个小时”。 百分号(%) 表示“每"。例如:*%10 * * * * echo hello world表示,每10分钟打印一回"hello world"。 表格说明: 域 是否必填 允许的值 分钟 是 0–59 小时 是 0–23 天 是 1–31 月份 是 1–12、JAN–DEC 星期中的某天 是 0–6 、SUN–SAT 2、非标准规则 仅由某些cron程序的扩展版本支持,标准版本并不支持。以下这部分是在维基百科英文版本部分就着谷歌大概翻译出来的,如果有误,请以维基百科词条中的原文内容为准,词条链接在文末。 L:“L”代表“最后”。 当在星期字段中使用时,它允许指定诸如给定月份的“最后一个星期五”(“5L”)之类的构造。 在day-of-month字段中,它表示该月的最后一天。 W:'W' 字符允许用于日期字段。 此字符用于指定离给定日期最近的工作日(周一至周五)。 例如,如果将“15W”指定为day-of-month字段的值,则其含义为:“距该月的15日最近的工作日”。 因此,如果15号是星期六,触发器会在14号星期五触发。 如果15日是星期日,触发器会在16日星期一触发。 如果15号是星期二,那么它会在15号星期二触发。 但是,如果将“1W”指定为月份中的某天的值,并且第1天是星期六,则触发器会在第3天的星期一触发,因为它不会“跳过”一个月的天数边界。 仅当月中的某一天是一天,而不是天范围或天列表时,才可以指定“W”字符 #:'#' 允许用于星期字段,并且后面必须跟一个1到5之间的数字。 它允许指定诸如给定月份的“第二个星期五”之类的结构。 例如,在星期字段中输入5#3对应于每个月的第三个星期五 ?:用于代替“*``**”以将月中的某天或一周中的某天留空 /:用于表示跳过某些给定的数。例如,*/3在小时域中等于0,3,6,9,12,15,18,21等被3整除的数; H:'H'表示替换了“散列”值。 因此不是一个固定的数字,例如表示每小时后的20分钟,表示该任务在一个未指定但不变的时间执行一次。 这允许随着时间的推移分散任务,而不是让所有任务同时开始并争夺资源。 0x04.其他 1、定时任务生效时间 需要注意的是,添加定时任务之后crontab需要等待几分钟才会生效,若要使立即生效需要重启cron服务: service cron restart 2、定时任务不生效 如果crontab定时任务不生效,可以排查以下几点: 1、Linux的时间与互联网时间不一致,而crontab中写的互联网时间 2、定时执行的.sh文件无执行权限 3、crontab进程未启动,crontab进程会每分钟去扫描/etc/crontab中的定时任务,故修改后无需重启该进程(重启只会让定时配置马上生效) 4、crontab进程配置文件中未指定具体执行用户 3、环境变量相关问题 在crontab文件中定义多个调度任务时,需要特别注意的一个问题就是环境变量的设置,因为我们手动执行某个脚本时,是在当前shell环境下进行的,程序能找到环境变量;而系统自动执行任务调度时,除了默认的环境,是不会加载任何其他环境变量的。因此就需要在crontab文件中指定任务运行所需的所有环境变量。 不要假定cron知道所需要的特殊环境,它其实并不知道。所以用户要保证在shell脚本中提供所有必要的路径和环境变量,除了一些自动设置的全局变量。以下三点需要注意: 脚本中涉及文件路径时写绝对路径; 脚本执行要用到环境变量时,通过source命令显式引入,例如: #!/bin/sh source /etc/profile 当手动执行脚本没问题,但是crontab不执行时,可以尝试在crontab中直接引入环境变量解决问题,例如: * * * * * . /etc/profile; /xx/xx/test.sh 参考资料: Linux crontab 命令 | 菜鸟教程 (runoob.com) cron - Wikipedia Cron - 维基百科,自由的百科全书 (wikipedia.org) OpenWrt任务定时cron_hzlarm的博客-CSDN博客_openwrt 定时任务
-
SQL系列总结(四):DCL(数据控制语言) 前排提示: 本篇博客篇幅较长,建议结合目录进行阅读! 目录: 前言 0x01.权限的授予与收回 GRANT REVOKE 0x02.数据库角色 角色的创建 ——CREATE ROLE 给角色授权 ——GRANT 将角色授予给其他角色或用户 ——GRANT 收回角色权限 ——REVOKE 0x03.用户管理 创建用户: 删除用户: 重命名用户名: 修改用户密码: 环境说明: 数据库:Mysql 5.5 连接软件:Navicat 前言 SQL总结系列目录: SQL系列总结(一):DDL(数据定义语言)- Roookie博客 | 记录 · 收纳 · 分享 (wlplove.com) SQL系列总结(二):DQL(数据查询语言)- Roookie博客 | 记录 · 收纳 · 分享 (wlplove.com) SQL系列总结(三):DML(数据操纵语言) - Roookie博客 | 记录 · 收纳 · 分享 (wlplove.com) SQL系列总结(四):DCL(数据控制语言) - Roookie博客 | 记录 · 收纳 · 分享 (wlplove.com) SQL系列总结(五):TCL(事务控制语言) - Roookie博客 | 记录 · 收纳 · 分享 (wlplove.com) 数据控制语言(Data Control Language,DCL),是一种可对数据访问权进行控制的指令,它可以控制特定用户账户对数据表、查看表、存储程序、用户自定义函数等数据库对象的控制权。由GRANT和REVOKE两个指令组成。 0x01.权限的授予与收回 用户对某一数据对象的操作权称为权限。 数据库管理员拥有对数据库中所有对象的所有权限。 用户对自己建立的基本表和视图拥有全部的操作权限。 关系数据库系统中数据库模式的存取权限: 对象 操作权限 SCHEMA(模式) CREATE VIEW(视图) CREATE TABLE(基本表) CREATE、ALTER INDEX(索引) CREATE 关系数据库系统中数据的存取权限: 对象 操作权限 TABLE(基本表)、VIEW(视图) CREATE、INSERT、SELECT、UPDATE、DELETE、REFERENCES、ALL PRIVILEGES 属性列 SELECT、INSERT、UPDATE、REFERENCES、ALL PRIVILEGES SQL中使用GRANT和REVOKE语句向用户授予或收回对数据的操作权限。 GRANT GRANT语句向用户授予权限,一般格式为: GRANT <权限> ON <对象类型><对象名> TO <用户> [WITH GRANT OPTION]; 其语义为:将对某个操作对象(基本表、视图等)的指定操作权限授予某个用户 执行GRANT语句的可以是数据库管理员,也可以是数据库对象创建者(即owner)或者已经拥有该权限的用户 接受权限的用户可以是一个或多个具体用户,也可以是PUBLIC,即全体用户 [WITH GRANT OPTION]子句是可选的,如果指定了这个子句,则表示获得权限的用户还可以把这种权限再授予其他的用户(仅限于获得的这些权限),此时这些权限可以称为依赖权限。反之则该用户不能传播该权限 SQL标准允许具有WITH GRANT OPTION的用户把相应权限或其子集传递授予其他用户,但不允许循环授权,即被授权者不能把权限再授回给授权者或其祖先 例1:把查询Student表的权限授给用户U1,并允许U1将此权限授予给其他用户 GRANT SELECT ON TABLE Student TO U1 WITH GRANT OPTION; 例2:把对Student表和Course表的全部操作权限授予用户U2和U3 GRANT ALL PRIVILEGES ON TABLE Student,Course TO U2 U3; 例3:把对表SC的所有权限授予给全体用户 GRANT ALL PRIVILEGES ON TABLE SC TO PUBLIC; 例4:把查询Student表格修改学生学号的权限授给用户U4 GRANT ALTER(Sno) ON TABLE Student TO U4; 查看当前用户拥有的权限: SHOW GRANTS; 查看指定用户拥有的权限,前提是有超级用户权限: SHOW GRANTS FOR <用户名>; REVOKE REVOKE语句收回已经授予给用户的权限,一般格式为: REVOKE [GRANT OPTION FOR] <权限> ON <对象类型> <对象名> FROM <用户> [CASCADE | RESTRICT] [GRANT OPTION FOR]是可选项。如果声明了GRANT OPTION FOR,那么只是撤销对该权限的授权的权力,而不是撤销该权限本身 关于REVOKE中的CASCADE与RESTRICT的区别: 在赋予了用户A某一权限以及对该权限授权的权力之后, 情况一:用户A并未将权限授予给其他用户,用REVOKE语句回收权限时不管加CASCADE还是RESTRICT情况都是一致的。表示的都是回收用户A的权限以及对该权限授权的权力; 情况二:用户A将权限赋予给了用户B和C,此时数据库中存在依赖权限(定义见上条),那么: CASCADE意思为级联操作,加CASCADE参数表示回收用户A的权限以及对该权限授权的权力以及用户B和用户C的依赖权限 RESTRICT意思为限制操作,因为此时存在依赖权限(可以认为是一种限制),加RESTRICT参数之后将会拒绝执行语句,除非限制解除(依赖权限不存在) 总结一下: CASCADE选项表示DBMS撤销指定的权限以及依赖于被撤销权限的所有权限。RESTRICT选项表示DBMS服务器在存在任何依赖权限不要撤销指定的权限。 以上纯为个人理解,可能会有错误。因为书上与网上对REVOKE中的CASCADE和RESTRICT这部分解释的很笼统,基本都是模棱两可地在解释CASCADE(其中网上大部分结果都是复制粘贴外网上的同一篇文章),而RESTRICT基本都没有解释。对着翻译查了部分英文资料,大概有了一些理解,可能不太准确。如有错误还望不吝赐教,请在文末评论区留言指出。 用户可以自主地决定将数据的存取权限授予何人,以及是否也将“授权”的权限授予别人,因此称这样的存取控制是自主存取控制。 例1:把用户U4修改学生学号的权限收回 REVOKE ALTER ON TABLE Student FROM U4; 例2:收回所有用户对表SC的查询权限 REVOKE SELECT ON TABLE SC FROM PUBLIC; 例3:把用户U5对SC表的INSERT权限收回,其中U5的INSERT权限还赋予给了U6、U7 REVOKE INSERT ON TABLE SC FROM U5 CASCADE; # 这句指定加上了CASCADE参数,在收回U5的INSERT权限的同时还收回了U5赋予给U6、U7的INSERT权限。 0x02.数据库角色 数据库角色是被命名的一组与数据库操作相关的权限,角色是权限的集合。 使用角色来管理数据库权限可以简化授权的过程:在SQL中首先用CREATE ROLE语句创建角色,然后用GRANT语句给角色授权,用REVOKE语句收回授予角色的权限。 角色的创建 ——CREATE ROLE CREATE ROLE <角色名>; 刚创建的角色为空,没有任何权限的。 给角色授权 ——GRANT 语句与给用户授权类似,将用户名部分换成角色名即可: GRANT <权限> ON <对象类型> <对象名> TO <角色>; 将角色授予给其他角色或用户 ——GRANT GRANT <角色> TO <角色>/<用户> [WITH ADMIN OPTION]; 该语句把角色授予某个用户或者某个角色,这样一个角色的所有权限就是授予它的全部角色所包含的权限的总和。 [WITH ADMIN OPTION]子句是可选的,如果声明了WITH ADMIN OPTION子句,则获得了权限的角色或者用户还可以把权限再授予给其他的角色 收回角色权限 ——REVOKE 同样的,与收回用户的权限语句类似: REVOKE <权限> ON <对象类型> <对象名> FROM <角色>; REVOKE操作的执行者是角色的创建者或者拥有这些角色的ADMIN OPTIION。 0x03.用户管理 创建用户: CREATE USER <用户名> IDENTIFIED BY <密码>; 注意:密码部分记得加引号,否则会报错 删除用户: -- 普通删除: DROP USER <用户名>; -- 级联删除,把该用户的相关关系也删除掉: DROP USER <用户名> CASCADE; -- DELETE语句也可以删除用户 DELETE USER FROM MYSQL.USER WHERE USER='用户名'; FLUSH PRIVILEGES; 重命名用户名: RENAME USER <旧用户名> TO <新用户名>; 修改用户密码: -- 密码部分记得加引号 SET PASSWORD=PASSWORD('新密码'); -- 或者 UPDATE USER SET PASSWORD=PASSWORD('新密码') WHERE USER='用户名'; -- mysql8.0以上版本也可以用此命令: ALTER USER <用户名> IDENTIFIED BY <密码>; 或者可以直接在控制台上用mysqladmin命令修改密码: mysqladmin -u <用户名> -p password 注意:MySQL中用户数据和权限修改后,若希望在不重启MySQL服务的情况下直接生效,那么就需要执行这个命令: FLUSH PRIVILEGES; -- flush privileges 命令本质上是将当前user和privilige表中的用户信息/权限设置从mysql库(MySQL数据库的内置库)中提取到内存里。 否则就需要重启Mysql服务: # Linux系统下: systemctl restart mysql # 或者 service mysql restart # Win10系统,管理员权限运行cmd窗口 net stop mysql net start mysql 主要参考资料: 《数据库系统概论(第5版)》 王珊 萨师煊 编著 mysql用户操作和权限管理 - gg火花 - 博客园 (cnblogs.com)
-
SQL系列总结(三):DML(数据操纵语言) 前排提示: 本篇博客篇幅较长,建议结合目录进行阅读! 目录: 前言 准备数据 0x01.插入数据 1.插入元组 2.插入子查询结果 0x02.修改数据 1.普通修改 2.带有子查询的修改语句 0x03.删除数据 1.普通删除 2.带有子查询的删除语句 环境说明: 数据库:Mysql 5.5 连接软件:Navicat 前言 SQL总结系列目录: SQL系列总结(一):DDL(数据定义语言)- Roookie博客 | 记录 · 收纳 · 分享 (wlplove.com) SQL系列总结(二):DQL(数据查询语言)- Roookie博客 | 记录 · 收纳 · 分享 (wlplove.com) SQL系列总结(三):DML(数据操纵语言) - Roookie博客 | 记录 · 收纳 · 分享 (wlplove.com) SQL系列总结(四):DCL(数据控制语言) - Roookie博客 | 记录 · 收纳 · 分享 (wlplove.com) SQL系列总结(五):TCL(事务控制语言) - Roookie博客 | 记录 · 收纳 · 分享 (wlplove.com) 数据操纵语言(Data Manipulation Language, DML)是对于数据库中的数据的基本操作。具体操作增、删、改这三种,对应的关键词是:增——INSERT、删——DELETE、改——UPDATE。 在使用数据库的系统开发过程中,对于数据库的基本操作就是“增、删、改、查”,以“CRUD”(分别为 Create, Read, Update, Delete)来称呼。 准备数据 本篇博客中出现的SQL语句实例基于下面的三张数据表: {tabs} {tabs-pane label="学生表"} Student(Sno,Sname,Ssex,Sage,Sdept) -- 创建表: CREATE TABLE Student(Sno CHAR(6) Primary KEY, -- 学号 主键 Sname VARCHAR(20), -- 名字 Ssex CHAR(2), -- 性别 Sage INT, -- 年龄 Sdept VARCHAR(20) -- 系部 )ENGINE=INNODB DEFAULT CHARSET=utf8; -- 插入数据: INSERT INTO Student VALUES('202101','李勇','男',20,'计算机系'); INSERT INTO Student VALUES('202102','刘晨','女',19,'计算机系'); INSERT INTO Student VALUES('202103','王敏','女',18,'数学系'); INSERT INTO Student VALUES('202104','张立','男',18,'信息系'); {/tabs-pane} {tabs-pane label="课程表"} Course(Cno,Cname,Cpno,Ccredit) -- 创建表: CREATE TABLE Course(Cno CHAR(1) PRIMARY KEY, -- 课程号 主键 Cname VARCHAR(20), -- 课程名 Cpno CHAR(1), -- 前置学科课程号 Ccredit INT -- 学分 )ENGINE=INNODB DEFAULT CHARSET=utf8; -- 插入数据: INSERT INTO Course VALUES('1','数据库','5',4); INSERT INTO Course VALUES('2','数学','null',2); INSERT INTO Course VALUES('3','信息系统','1',4); INSERT INTO Course VALUES('4','操作系统','6',3); INSERT INTO Course VALUES('5','数据结构','7',4); INSERT INTO Course VALUES('6','数据处理','',2); INSERT INTO Course VALUES('7','C语言','6',4); {/tabs-pane} {tabs-pane label="学生选课表"} SC(Sno,Cno,Grade) -- 创建表: CREATE TABLE SC(Sno CHAR(6), -- 学号 主键 Cno CHAR(1), -- 课程号 主键 Grade INT, -- 成绩 PRIMARY key(Sno,Cno) -- 设置表级约束条件 )ENGINE=INNODB DEFAULT CHARSET=utf8; -- 插入数据: INSERT INTO SC VALUES('202101','1',92); INSERT INTO SC VALUES('202101','2',85); INSERT INTO SC VALUES('202101','3',88); INSERT INTO SC VALUES('202102','2',90); INSERT INTO SC VALUES('202102','3',80); {/tabs-pane} {/tabs} 0x01.插入数据 SQL数据插入语句有两种形式,一种是插入一个元组(即一行数据),另一种是插入子查询结果,子查询结果可以是多个元组(多行数据)。 1.插入元组 为表中所有字段都添加数据: INSERT INTO <表名> VALUES(<数据1>,<数据2> ···); INTO子句中并没有指明任何属性,表示给所有字段添加值,因此新插入的元组必须在每个属性列上都具有值。 VALUE子句对新元组的各属性列赋值,括号中属性列的次序与CREATE TABLE中的属性次序一一对应。 例:将一个新学生的全部数据插入到Student表中。(学号:202105,姓名:陈东,性别:男,所在系:信息系,年龄:18) INSERT INTO Student VALUES("202105","陈东","男",18,"信息系"); 当在INTO子句中指明部分属性列名时,表示仅对这几项属性进行赋值: INSERT INTO <表名> (<属性列1>,<属性列2> ···) VALUES(<数据1>,<数据2> ···); INTO子句指出了要在哪些属性上赋值,没有出现的属性类将默认取空值。其中,表定义时说明了NOT NULL的属性列不能取空值,否则会报错 VAlUE子句中属性的顺序可以与CREATE TABLE中的顺序不一样,但必须与INTO子句中的属性字段一一对应 例:向选课表中插入一条选课记录 (学号:202103,课程号:1) INSERT INTO SC (Sno,Cno) VALUES('202103','1'); 2.插入子查询结果 子查询不仅可以嵌套在SELECT语句中来构造父查询的条件,也可以嵌套在INSERT语句中用以生成要插入的批量数据。其语句格式为: INSERT INTO <表名> (<属性列1>,<属性列2> ···) [子查询语句]; -- 可以理解为在原来查询语句的基础上将VALUE子句变为了子查询语句 0x02.修改数据 1.普通修改 修改操作也称为更新操作,其语句的一般格式为: UPDATE <表名> SET <列名>=<表达式>,<列名>=<表达式>··· [WHERE <条件>]; 其功能是修改指定表中满足WHERE子句条件的元组 SET子句后的等式表示给要修改的属性赋予新值,用于取代原来的属性列值 例:将学生李勇的年龄改为22 UPDATE Student SET Sage='22' WHERE Sname='李勇'; 如果省略WHERE子句,则修改的对象为表中的所有元组 例:将所有的学生的年龄增加一岁 UPDATE Student SET Sage=Sage+1 2.带有子查询的修改语句 子查询也可以嵌套在UPDATE语句中,用以构造修改的条件。 例:将计算机系全体学生的成绩置零 UPDATE SC SET Grade=0 WHERE Sno IN (SELECT Sno FROM Student WHERE Sdept="计算机系"); 0x03.删除数据 1.普通删除 删除语句的一般格式为: DELETE FROM <表名> WHERE <条件>; DELETE语句执行完之后会返回删除的行数以及WHERE条件匹配的行数。 例:删除学号为202103的学生记录 DELETE FROM Student WHERE Sno='202103'; 删除学号为202101,202102,202103的学生记录 DELETE FROM Student WHERE Sno IN ('202101','202102','202103'); WHERE子句可以省略,此时为清空全表数据。请注意是数据的删除,表的结构依然存在。如: 例:删除所有学生的选课记录 DELETE FROM SC;-- 执行结果就是表SC变成了一个空表 2.带有子查询的删除语句 同修改语句,子查询也可以嵌套在DELETE语句中,用来构造执行删除操作的条件。 例:删除系所有学生的选课记录 DELETE FROM SC WHERE Sno IN (SELECT Sno FROM Student WHERE Sdept='信息系'); 主要参考资料:《数据库系统概论(第5版)》 王珊 萨师煊 编著
-
SQL系列总结(二):DQL(数据查询语言) 前排提示: 本篇博客篇幅较长,建议结合目录进行阅读! 目录: 前言 准备数据 0x01.单表查询 1.基本查询 2.条件查询 比较大小 确定范围 确定集合 字符匹配 判断是否为空 多重条件 3.分页查询 0x02.连接查询 ——待完成 0x03.嵌套查询 ——待完成 0x04.集合查询 ——待完成 0x05.基于派生表的查询 ——待完成 环境说明: 数据库:Mysql 5.5 连接软件:Navicat 前言 SQL总结系列目录: SQL系列总结(一):DDL(数据定义语言)- Roookie博客 | 记录 · 收纳 · 分享 (wlplove.com) SQL系列总结(二):DQL(数据查询语言)- Roookie博客 | 记录 · 收纳 · 分享 (wlplove.com) SQL系列总结(三):DML(数据操纵语言) - Roookie博客 | 记录 · 收纳 · 分享 (wlplove.com) SQL系列总结(四):DCL(数据控制语言) - Roookie博客 | 记录 · 收纳 · 分享 (wlplove.com) SQL系列总结(五):TCL(事务控制语言) - Roookie博客 | 记录 · 收纳 · 分享 (wlplove.com) 数据查询是数据库的核心操作。因此,数据查询语言DQL(Data Query Language)是SQL中的核心部分,它允许用户查询数据,这也是通常最频繁的数据库日常操作。 SQL提供了SELECT进行语句查询,该语句具有灵活的使用方式和丰富的功能。SELECT语句既可以完成简单的单表查询,也可以完成复杂的连接查询和嵌套查询。 准备数据 本篇博客中出现的SQL语句实例基于下面的三张数据表: {tabs} {tabs-pane label="学生表"} Student(Sno,Sname,Ssex,Sage,Sdept) -- 创建表: CREATE TABLE Student(Sno CHAR(6) Primary KEY, -- 学号 主键 Sname VARCHAR(20), -- 名字 Ssex CHAR(2), -- 性别 Sage INT, -- 年龄 Sdept VARCHAR(20) -- 系部 )ENGINE=INNODB DEFAULT CHARSET=utf8; -- 插入数据: INSERT INTO Student VALUES('202101','李勇','男',20,'计算机系'); INSERT INTO Student VALUES('202102','刘晨','女',19,'计算机系'); INSERT INTO Student VALUES('202103','王敏','女',18,'数学系'); INSERT INTO Student VALUES('202104','张立','男',18,'信息系'); {/tabs-pane} {tabs-pane label="课程表"} Course(Cno,Cname,Cpno,Ccredit) -- 创建表: CREATE TABLE Course(Cno CHAR(1) PRIMARY KEY, -- 课程号 主键 Cname VARCHAR(20), -- 课程名 Cpno CHAR(1), -- 前置学科课程号 Ccredit INT -- 学分 )ENGINE=INNODB DEFAULT CHARSET=utf8; -- 插入数据: INSERT INTO Course VALUES('1','数据库','5',4); INSERT INTO Course VALUES('2','数学','null',2); INSERT INTO Course VALUES('3','信息系统','1',4); INSERT INTO Course VALUES('4','操作系统','6',3); INSERT INTO Course VALUES('5','数据结构','7',4); INSERT INTO Course VALUES('6','数据处理','',2); INSERT INTO Course VALUES('7','C语言','6',4); {/tabs-pane} {tabs-pane label="学生选课表"} SC(Sno,Cno,Grade) -- 创建表: CREATE TABLE SC(Sno CHAR(6), -- 学号 主键 Cno CHAR(1), -- 课程号 主键 Grade INT, -- 成绩 PRIMARY key(Sno,Cno) -- 设置表级约束条件 )ENGINE=INNODB DEFAULT CHARSET=utf8; -- 插入数据: INSERT INTO SC VALUES('202101','1',92); INSERT INTO SC VALUES('202101','2',85); INSERT INTO SC VALUES('202101','3',88); INSERT INTO SC VALUES('202102','2',90); INSERT INTO SC VALUES('202102','3',80); {/tabs-pane} {/tabs} 0x01.单表查询 单表查询是指仅涉及一个表的查询。是DQL的基础部分。 1.基本查询 基本表的查询很简单,查询指定表的所有数据: SELECT * FROM <表名>; -- 查询结果是一个二维表格 例:查询全体学生的详细信息 SELECT * FROM Student; 也可以查询指定列: SELECT <列名1>,<列名2>··· FROM <表名>; 例:查询全体学生的学号姓名信息 SELECT Sno,Sname FROM Student; 有时候查询出来的列会有重复值,可以用DISTINCT来消除它们: SELECT DISTINCT Sno,Sname FROM Student; 或者在查询中加入计算表达式。 例:查询全体学生的姓名、出生时间信息 SELECT Sname,2021-Sage FROM Student; SELECT语句也可以去掉FROM子句,如: SELECT 1; # 返回结果1 SELECT 1+1; # 返回结果2 这种只有表达式却没有FROM子句的SELECT语句会直接计算出表达式的结果并返回一个列名为表达式、值为计算结果的1*1表格。可以用来判断当前连接与数据库的连接是否有效。 2.条件查询 大部分查询数据中,我们只是需要部分数据,而不是全部数据。因此就需要加上一些条件来筛选掉不需要的数据,可以通过`WHERE关键字后加入相应的查询条件来实现。 WHERE子句常用到的查询条件如下: 查询条件 谓词 比较 =、>、<、>=、<=、!=、<>、!>、!< 确定范围 BETWEEN ... AND... 、NOT BETWEEN ... AND ... 确定集合 IN、NOT IN 字符匹配 LIKE、NOT LIKE 判断是否为空 IS NULL、IS NOT NULL 多重条件/逻辑运算 AND、OR、NOT 比较大小 例1:查询李勇同学的详细信息 SELECT * FROM Student WHERE Sname='李勇'; 例2:查询考试成绩不及格的学生的学号 SELECT Sno FROM SC WHERE Grade<60; 例3:查询所有年龄在20岁以下的学生姓名及其年龄 SELECT Sname,Sage FROM WHERE Sage<20; 确定范围 BETWEEN···AND··· 和NOT BETWEEN···AND···可以用来查找属性值在(或不在)指定范围的元组,其中BETWEEN后是范围的下限(即低值),AND后是范围的上限(即高值)。 例:查询年龄在18~23岁的学生的学号、姓名 SELECT Sno,Sname FROM Student WHERE Sage BEWEEN 18 AND 23; 确定集合 谓词IN可以用来查找属性值属于指定集合的元组。 例:查询计算机系全体学生的名单 SELECT Sname FROM Student WHERE Sdept IN ('计算机系'); 字符匹配 谓词LIKE可以用来进行字符串的匹配。其一般语法格式如下: [NOT] LIKE '<匹配串>' [ESCAPE '<换码字符>'] <匹配串>可以是一个完整的字符串,也可以含有`通配符%和_。字符匹配规则如下: %(百分号)代表任意长度的字符串。 例如a%b表示以a开头,以b结尾的任意长度的字符串,如abc、abdewc、ab等都满足该匹配串 _(下划线)代表任意单个字符 例如a_b表示以a开头,以b结尾的长度为3的任意字符串。如abc、afb等都满足该匹配串。 例1:查询所有姓“刘”的学生的学号、姓名和性别 SELECT Sname,Sno,Ssex FROM Student WHERE Sname LIKE '刘%'; 例2:查询姓“欧阳”且全名为三个字的学生的姓名和学号 SELECT Sname,Sno from Student WHERE Sname LIKE='欧阳_'; 例3:查询所有不姓“王”的学生的姓名、学号和性别 SELECT Sname,Sno,Ssex WHERE Sname NOT LIKE '王%'; 若用户要查询的字符串本身就含有通配符%或者_,这时就要使用ESCAPE ‘<换码字符>’短语对通配符进行转义了。 例1:查询DB_Design这门课程的课程号和学分 SELECT Cno,Ccredit FROM Course WHERE Cname='DB\_Designer' ESCAPE '\'; 例2:查询以“DB_”开头,且倒数第三个字符为i的课程的详细情况 SELECT * FROM Course WHERE Cname='DB\_%i__' ESCAPE '\'; 判断是否为空 IS NULL与IS NOT NULL用来判断条件是否为空 例:查询成绩表中只有选课记录却没有成绩的学生的学号和课程号 SELECT Sno,Cno FROM SC WHERE Grade IS NULL; 多重条件 逻辑运算符AND和OR可用来连接多个查询条件。其中AND的优先级高于OR,但可以通添加括号来改变优先级。 例:查询计算机系年龄在20岁以下的学生姓名 SELECT Sname FROM Student WHERE Sage<20; 3.分页查询 在进行表的查询时,若一次查询出来的数据数量很多的话,放在一个页面显示的话数据量太大,不如分页显示,每次显示n条,这就是分页查询。 要实现分页功能,实际上就是从结果集中显示第1~n条记录作为第1页,显示第n+1~2n条记录作为第2页,依次类推。 因此,分页实际上就是从结果集中“截取”出第M~N条记录。这个查询可以通过LIMIT <M> OFFSET <N>子句实现。 SELECT * FROM <表名> LIMIT <M> OFFSET <N>; 例:在学生表中查询第二页学生数据,每一页三项数据 SELECT * FROM Student LIMIT 4 OFFSET 6; 0x02.连接查询 ——待完成 0x03.嵌套查询 ——待完成 0x04.集合查询 ——待完成 0x05.基于派生表的查询 ——待完成 主要参考资料:《数据库系统概论(第5版)》 王珊 萨师煊 编著
-
SQL系列总结(一):DDL(数据定义语言) 前排提示: 本篇博客篇幅较长,建议结合目录进行阅读! 目录 前言 SQL简介 数据字典 定义: 0x01.模式 创建模式——CREATE SCHEMA 删除模式——DROP SCHEMA 0x02.基本表 数据类型 创建表 删除表 修改表 0x03.索引 索引类型 建立索引 修改索引名称 删除索引 0x04.视图 定义 特征 几个概念 创建视图 查询视图 更新视图 删除视图 总结 环境说明: 数据库:Mysql 5.5 连接软件:Navicat 前言 SQL总结系列目录: SQL系列总结(一):DDL(数据定义语言)- Roookie博客 | 记录 · 收纳 · 分享 (wlplove.com) SQL系列总结(二):DQL(数据查询语言)- Roookie博客 | 记录 · 收纳 · 分享 (wlplove.com) SQL系列总结(三):DML(数据操纵语言) - Roookie博客 | 记录 · 收纳 · 分享 (wlplove.com) SQL系列总结(四):DCL(数据控制语言) - Roookie博客 | 记录 · 收纳 · 分享 (wlplove.com) SQL系列总结(五):TCL(事务控制语言) - Roookie博客 | 记录 · 收纳 · 分享 (wlplove.com) SQL简介 SQL(Structured Query Language),称为结构化查询语言,是关系数据库的标准语言。其功能不仅仅是查询,而是包括数据库模式创建、数据库数据的插入与修改、数据库安全性完整性控制等一系列功能。 目前没有一个关系数据库系统(RDBMS)能够支持SQL标准的所有概念和特性。大部分数据库系统能支持SQL/92标准的大部分功能以及SQL99、SQL2003中的部分新概念。同时许多软件厂商对SQL基本命令集还进行了不同程度的扩充和修改,又可以支持标准以外的一项功能特性。因此,使用具体数据库系统时还需要参考相应的官方文档。 SQL总共由以下几部分组成: 数据查询语言(DQL: Data Query Language):其语句也称为“数据检索语句”,用以从表中获得数据,确定数据怎样在应用程序给出。 数据操纵语言(DML:Data Manipulation Language):用于添加、修改和删除。 数据控制语言(DCL:Data Control Language):实现权限控制,确定单个用户和用户组对数据库对象的访问。 数据定义语言(DDL:Data Definition Language):在数据库中创建新表或修改、删除表(CREATE TABLE 或 DROP TABLE);为表加入索引等。 数据字典 定义: 数据字典是关系型数据库内部的一组系统表,他记录数据库中所有的定义信息,包括关系模式定义、视图定义、索引定义、完整约束定义、各类用户对数据库的操作权限、统计信息等。 关系型数据库在执行SQL的数据定义语句时,实际上就是更新数据库字典表中的相应信息。 进行查询优化和查询处理时,数据字典中的信息是其重要依据。 本篇只涉及到DDL,即数据定义语言。如无特别说明,本篇博客中方括号内容表示可选内容。 SQL中的数据定义功能包括模式定义、表定义、视图和索引定义。 0x01.模式 创建模式——CREATE SCHEMA CREATE SCHEMA <模式名> AUTHORIZATION <用户名>; 若不指定模式名,则默认为用户名 用户需要有数据库管理员权限或者获得了管理员授予的CREATE SCHEMA权限才能创建模式 定义模式实际上定义了一个命名空间,用户在创建模式的同时可以在这个模式中创建基本表、视图、定义授权等。即: CREATE SCHEMA <模式名> AUTHORIZATION <用户名> [<表定义子句>|<视图定义子句>|<授权定义子句>]; 删除模式——DROP SCHEMA DROP SCHEMA <模式名> <CASCADE|RESRICT>; # CASCADE(级联)和 RESTICT(限制)两者必选其一 0x02.基本表 数据类型 数据类型 含义 CHAR(n),CHARACTER(n) 长度为n的定长字符串 VARCHAT(n),CHARACTERVARYING(n) 最大长度为n的变长字符串 CLOB 字符串大对象 BLOB 二进制大对象 INT,INTEGER 长整数(4字节) SMALLINT 短整数(2字节) BIGINT 大整数(8字节) NUMERIC(p,d) 定点数,由p位数字(不包括小数点、符号)组成,小数点后面有d位数字 DECIMAL(p,d),DEC(p,d) 同NUMERIC REAL 取决于机器精度的单精度浮点数 DOUBLE PRECISION 取决于机器精度的双精度浮点数 FLOAT(n) 可选精度的浮点数,精度至少为n位数字 BOOLEAN 布尔类型 DATE 日期,包含年、月、日,格式为YYYY-MM-DD TIME 时间,包含一日的时、分、秒,格式为HH:MM:SS TIMESTAMP 时间戳 INTERVAL 时间间隔类型 这里要说明的是,不同的数据库产品支持的数据类型并不完全相同,具体使用时还需参考官方文档。 创建表 CREATE TABLE <表名> (<列名1> <数据类型> [列级完整性约束条件1], <列名2> <数据类型> [列级完整性约束条件2], ... [<表级完整性约束条件>]); 附:常用到的与表有关的约束条件: NOT NULL:非空约束 UNIQUE:唯一约束 PRIMARY KEY:主键约束 FROEIGN KEY:外键约束 CHECK:校验约束 查看当前数据库有多少表: # 选中某一个数据库 USE <数据库名>; # 查看该数据库的所有表 SHOW TABLES; 删除表 DROP TABLE <表名> [RESTRICT|CASCADE]; RESTRICT与CASCADE的区别: RESTRICT指限制删除,表示该表的删除是有限制条件的:即该表不能被其他表的约束所引用(如CHECK,FOREIGN KEY等约束),不能存在依赖于该表的对象,比如视图、触发器、存储过程或者函数等。只有当这些限制条件不存在时,才能允许删除。 CASCADE指级联删除,加上此参数之后则该表的删除没有限制条件。在删除基本表的同时,相关的对象,例如视图等,都将被一起删除。 如果不指定删除类型时,默认是RESTRICT。 修改表 这里的修改针对的是基本表的结构(如添加删除列、或者修改数据类型),并不是基本表的数据。对于基本表数据的修改属于DML的范围,本篇博客只涉及到DDL。 添加新列 ALTER TABLE <表名> ADD [COLUMN] <新列名> <数据类型> [完整性约束]; # 给已存在的列添加列级完整性约束 ALTER TABLE <表名> ADD [列级完整性约束条件]; 添加新的表级约束条件 ALTER TABLE <表名> ADD <表级完整性约束条件>; 删除指定列 ALTER TABLE <表名> DROP [COLUMN] <列名> [CASCADE|RESTRICT]; 删除指定的完整性约束条件 ALTER TABLE <表名> DROP CONSTRAINT <完整性约束名> [RESTRICT|CASCADE]; 修改表中已存在的列 ALTER TABLE <表名> ALTER COLUMN <列名> <数据类型>; 0x03.索引 建立索引的目的:加快查询速度 缺点:索引虽然能够加速数据库查询,但需要占用一定的存储空间,并且当基本表更新时,索引也需要进行相应的维护。这些都会增加数据库的负担,因此要根据实际应用的需要有选择地创建索引。 索引类型 目前SQL标准中没有涉及索引,但商用关系数据库系统一般都会支持索引机制,且不同数据库支持的索引类型不尽相同。 顺序文件上的索引:针对按指定属性值升序和降序存储的关系,在该属性上建立一个顺序索引文件,索引文件由属性值和相应的元组指针组成。 B+树索引:将索引属性组织成 B+树的形式,B+树的叶节点为属性值和相应的元组指针。B+树索引具有动态平衡的优点。 散列(hash)索引:建立若干个桶,将索引属性按照其散列函数映射到相应桶中,桶中存放索引属性和相应的元组指针。散列 索引具有查找速度快的特点。 位图索引:用位向量记录索引属性中可能出翔的值,每个位向量对应一个可能值。 建立索引 CREATE [UNIQUE] [CLUSTER] INDEX <索引名> ON <表名> (<列名1>[<次序1>],···); <表名>是要建索引的基本表的名字 索引可以建立在该表的一列或者多列上,各列名之间用逗号分隔没每个列名后妈可以用<次序>指定索引值的排列次序,可选ASC(升序)或者DESC(降序)。默认ASC。 UNIQUE表明此索引的每一个索引值只对应唯一的数据记录。 CLUSTER此索引是聚簇索引。 修改索引名称 ALTER INDEX <旧索引名> RENAME TO <新索引名>; 要修改索引本身的话,建议删除再重建。 删除索引 DROP INDEX <索引名> 索引一经建立就由系统使用和维护,无需用户干预。 删除索引是由于数据库频繁进行增、删、改,系统便会花费许多时间来维护索引,从而降低查询效率,这是便可以删除一些不必要的索引。 索引删除后,数据字典上关于索引的描述也会被删除。 0x04.视图 定义 视图是从一个或几个基本表(或者视图)导出的表。 视图一经定义,就可以和基本表一样被查询、被删除。也可以在一个视图上再定义新的视图,但对视图的更新(增、删、改)操作则有一定的限制。 特征 数据库只存放视图的定义,而不存放视图中对应表的数据(否则数据库中便存放了很多相同的数据),这些数据仍存放在原来的基本表中。 归根到底,视图与“图”无关,其实质上还是表。只不过由于不存放数据,只存放定义,因此称其为“虚表”。 几个概念 行列子集视图:建立在基本表之上,只是去掉了基本表的某些行和列,但保留了主键的这类视图。 分组视图:带有聚集函数和GROUP BY子句的查询的视图。 带表达式的视图:简单来说就是视图中存在基本表中不实际存在的列,即虚拟列。这些列是由基本表中的数据列经过各种计算派生出来的。 创建视图 CREATE VIEW <视图名> (<列名>,<列名>,<列名> ...) AS <子查询> [WITH CHECK OPTION]; <子查询>是针对基本表的SELECT语句,即从建立视图的基本表中选取部分数据,而不是全部数据 [WITH CHECK OPTION]是一个条件表达式,有这个条件表达式时,对视图进行UPDATE、INSERT和DELETE时如果要操作的行不满足这里的条件,则不允许进行 视图不仅可以建立在单个基本表上,也可以建立在多个基本表上 数据库执行CREATE VIEW语句的结果只是把视图的定义存入数据字典,并不执行其中的SELECT语句。只有在进行视图的查询时,才会执行SELECT语句。 组成视图的属性列名全部指定或者全部省略,没有第三种选择。 以下三种情况必须要指明视图的列名: 某个目标列并不是单纯的属性名,而是聚集函数或者列表达式 多表连接时选出了几个同名列作为视图的字段 需要在视图中为某个列启用新的更适合的名字 查询视图 视图其本质上还是表,因此可以对其进行查询。查询视图与查询表的语句基本相同。详见[DQL]()。 在视图查询的过程中,会经过视图消解,将对视图的查询转换为对基本表的查询。 视图消解:关系型数据库执行视图的查询操作时,首先进行有效性检查,即确定查询中涉及到的表、视图等是否都存在。如果存在,则从数据字典中取出视图的定义,把定义中的子查询和用户的查询结合起来,转换成等价的对基本表的查询,然后再执行修正了的查询。这一转换过程称之为视图消解。 局限:目前多数关系数据库对行列子集视图都能正确地转换。但对非行列子集视图的查询就不一定能做转换了,因此这类查询应该直接对基本表进行。 非行列子集视图:图中的部分列由其他表的列经过运算得出。 视图查询与基于派生表的查询的区别: 视图一旦定义,其定义将永久保存在数据字典中,之后的所有查询都可以直接饮用该视图。 而派生表知识在语句执行时临时定义,语句执行还定义即被删除。 更新视图 视图的更新包括INSERT、DELETE、UPDATE,其操作语句与表的操作语句基本相同。此处不再详述。详见[DML]()。 类似于视图的查询,对视图的更新同样是通过视图消解,转换为对基本表的更新操作。 目前各个关系数据库一般只允许对行列子集视图进行更新,而且不同的数据库对视图的更新还有更进一步的规定。由于各数据库系统实现方法上的差异,这些的规定也不尽相同。 删除视图 DROP VIEW <视图名> [CASCADE]; 视图删除实质上是将视图的定义从数据字典中删除。 CASCADE是可选的 若要删除的视图还导出了其他视图,那么加上CASCADE参数之后将会把该视图导出的视图一块删除。 总结 SQL可以分为数据定义(DDL)、数据查询(DQL)、数据更新(DML)、数据控制(DCL)四大部分。 综上,DDL中的基本操作可以用表格简单总结一下: 操作对象 创建 删除 修改 模式 CREATE SCHEMA DROP SCHEMA 表 CREATE TABLE DROP TABLE ALTER TABLE 视图 CREATE VIEW DROP VIEW 索引 CREATE INDEX DROP INDEX ALTER INDEX 主要参考资料:《数据库系统概论(第5版)》 王珊 萨师煊 编著
-
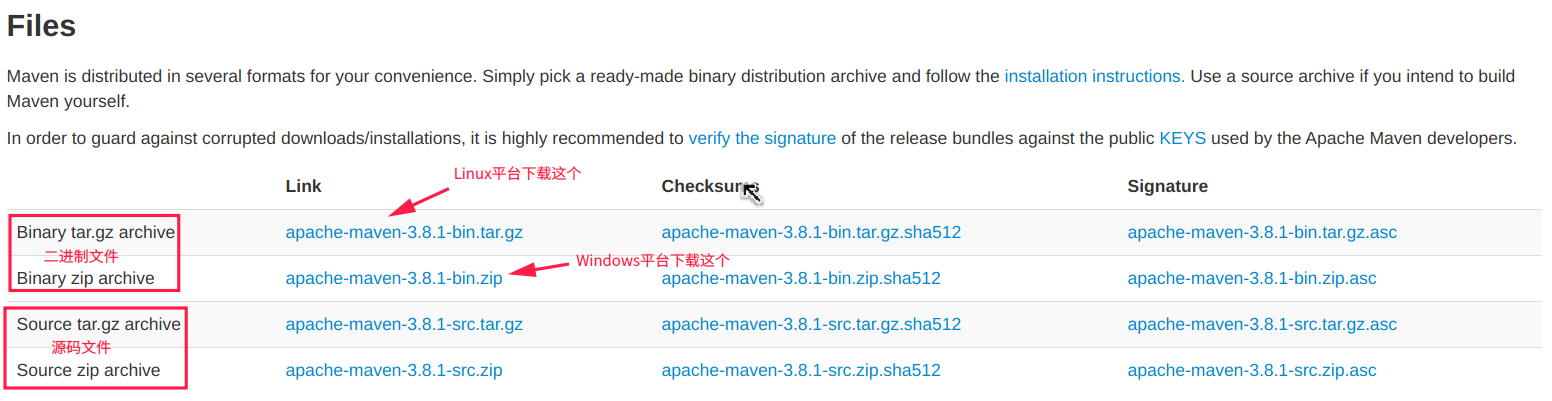
在IDEA中配置Maven开发环境 目录: 前言 1. 下载Maven安装文件 2.解压并配置环境变量 2.1、windows端 2.2、Linux端 3.设置IDEA 3.1 修改Maven全局配置文件 3.2 修改路径 3.3 导入Maven依赖 环境说明: 系统:win10专业版 deepin V20 IDE:IDEA 2020.3 java:jdk1.8 Maven:3.8.1 前言 Maven是一个构建自动化工具,主要用于Java项目,由Apache软件基金会托管,它以前是Jakarta项目的一部分。Maven还可用于构建和管理用 C#、Ruby、Scala 和其他语言编写的项目。 Maven解决了构建软件的两个方面:软件是如何构建的,以及它的依赖关系。与早期的工具(如Apache Ant)不同,它对构建过程使用约定,并且只需要写下异常。 XML 文件描述了正在构建的软件项目、它对其他外部模块和组件的依赖、构建顺序、目录和所需的插件。它带有预定义的目标,用于执行某些明确定义的任务,例如代码编译及其打包。 Maven从一个或多个存储库(例如Maven 2 Central Repository)动态下载Java库和Maven插件,并将它们存储在本地缓存中。下载工件的本地缓存也可以使用本地项目创建的工件进行更新。公共存储库也可以更新。 Maven官网:http://maven.apache.org/ 1. 下载Maven安装文件 Maven下载页面:http://maven.apache.org/download.cgi 进入下载页面,根据不同的系统选择前两个二进制文件之一下载就可以了。如果打算自行构建Maven,那就下载后面的源码文件。 2.解压并配置环境变量 部分参考资料:Maven – Installing Apache Maven 2.1、windows端 将下载下来的“.zip”压缩文件解压,这里以解压到“D:\Software”为例进行说明。 “计算机”图标上点击右键->属性->高级系统设置(win10 20H2需要在属性窗口的“相关设置”标签中才能找到高级系统设置),在高级系统设置窗口的右下角点击“环境变量”。 “环境变量”分为两种,一种是“用户变量”,这里面配置的环境变量只适用于当前计算机用户,另一种是“系统变量”,适用于这台计算机上的所有用户。具体设置成哪种环境变量看个人习惯。 添加如下两条环境变量,其中MAVEN_HOME的值是Maven文件的解压路径: 环境变量名称 环境变量值 MAVEN_HOME D:\Software\apache-maven-3.8.1 Path %MAVEN_HOME%\bin 其实第一个环境变量的名称并不是固定的,在其他的配置环境变量的教程中名称也可能不同。这个只是习惯而已,只要保证环境变量值没什么问题即可。 第二条Path也可以写成“D:\Software\apache-maven-3.8.1\bin”,这里引用了上条设置的MAVEN_HOME,表示的是Maven安装路径下的bin文件夹 全都添加完之后,两连“确定”完成环境变量的配置。 2.2、Linux端 Linux下也可以用以下命令下载安装包: wget https://mirrors.tuna.tsinghua.edu.cn/apache/maven/maven-3/3.8.1/binaries/apache-maven-3.8.1-bin.tar.gz 下载下来的是一个后缀名为“.tar.gz”的压缩包。解压压缩包到/usr/下: sudo tar -xvf apache-maven-3.8.1-bin.tar.gz -C /usr/ # 当然解压目录不一定非得是/usr/,换成其他目录也可以,后面配置环境变量时目录就要修改 修改环境变量,编辑/etc/profile文件: sudo nano /etc/profile 在末尾加入以下环境变量,“/usr/apache-maven-3.8.1”是Maven安装文件所在的目录: export PATH=/usr/apache-maven-3.8.1/bin:$PATH 然后ctrl + o保存,ctrl + x退出,再输入以下命令使环境变量生效: source /etc/profile 至此就算配置好了环境变量。使用“mvn -v”命令检验是否配置成功,若无法识别命令,部分Linux环境下可能还需要重启一遍电脑才能生效。 3.设置IDEA 此处以Win10下的IDEA开发环境为例,Linux下相关操作都是一样的。 在cmd控制台窗口中输入以下命令查看Maven版本,检验是否配置成功: mvn -v 没有错误的话,输出结果是这样: 3.1 修改Maven全局配置文件 Maven有一个全局配置文件,里面是Maven的一些设置,该文件存放在Maven安装路径的conf文件夹中,修改的就是这个配置文件。关于这个文件的详解可以看这篇:Maven全局配置文件settings.xml详解 - 洪墨水 - 博客园 (cnblogs.com) Maven需要一个文件夹来存放从Maven仓库下载到本地的依赖包,为了减少对系统盘的空间占用,建议将这个文件夹设置到其他分区。找到配置文件里的settings标签,在标签里面加上: <!-- 中间的路径是本地Maven依赖包的存放路径 --> <localRepository>D:\programmeSoftware\MavenRepository</localRepository> Maven仓库在国外,在国内下载速度比较慢,所以还需要将镜像源更改为国内的镜像源。找到<mirrors>标签,往标签内加入阿里云的镜像源配置: <mirror> <id>nexus-aliyun</id> <name>Nexus aliyun</name> <url>http://maven.aliyun.com/nexus/content/groups/public/</url> <mirrorOf>central</mirrorOf> </mirror> 3.2 修改路径 首先在IDEA中新建一个Maven项目,步骤与新建普通Java项目类似,项目类型选择成Maven。 依次点击“File”->“settings”(或者快捷键Ctrl+Alt+s)打开设置界面,然后选择“Build,Execution,Deployment”->“Maven”,设置如下: “User settings file”是Maven全局配置文件的存放路径,“Local repository”是从Maven仓库下载到本地的依赖包的存放路径。设置完了之后点击右下角“Apply”。 需要注意的是,这个设置仅适用于现在打开的Maven项目,为了将这个更改应用到新建的Maven项目上,还需要再进行设置。依次点击“File”->“New Projects Settings”->“Settings for New Projects...”,同样选择“Build,Execution,Deployment”->“Maven”,进行与上面同样的设置即可。 3.3 导入Maven依赖 Maven仓库地址:Maven Repository: Search/Browse/Explore (mvnrepository.com) 项目里用到的依赖包都是从这个网站上找的,以Mybatis为例,说一下依赖包的导入方式。 在网站顶部的搜索栏中搜索“Mabatis” 选择第一项,然后会看到该软件有很多个不同的版本,版本可以随便选择,但是一般为了防止项目中出现与软件版本相关的这类“玄学问题”,还是选择后面使用人数多的一项吧 点击版本号即可进入该版本界面,复制下方“Maven”标签下的那一串<dependency>标签 然后打开项目根目录下的pom.xml文件,将内容粘贴至<dependencies>(这个是复数的dependency)标签内部,注意缩进。导入依赖的第一步,完成。 当然由于只是导入了配置,本地并没有相应的依赖包,所以会看到粘贴的配置中会有红线报错,碰到报错先别慌,看第二步。此时需要在IDEA中要重载一遍项目的Maven依赖配置。有这么几种方法: 在左侧文件目录中的项目名称上单击右键,依次选择“Maven”->“Reload project” 在IDEA窗口右侧列表找到“Maven”,并单击展开菜单,点击菜单左上角刷新重载按钮 在打开的pom.xml文件界面上单击右键(只有在pom.xml文件上单击右键才可以,其他文件单击右键选项中没有Maven),依次选择“Maven”->“Reload project” 不管使用哪一种方式,最后结果都是窗口右下角会出现一个进度条,开始往本地下载pom.xml文件中导入的依赖项。等待这个进度条走完,原来的报错也就消失了。 在以后修改或添加了Maven依赖以后,都可以用这几种方法重新载入项目的Maven依赖配置。
-
ubuntu安装MongoDB数据库 目录: 前言 1、导入MongoDB公共 GPG 密钥 2、创建列表文件 3、用命令安装MongoDB 3.1 安装最新版本 3.2 安装指定版本 4.启动MongoDB 4.1 systemed(systemctl): 4.2 System V Init(service): 5.管理MongoDB数据库 6.卸载MongoDB 附:在更改MongoDB连接端口时遇到的坑 环境说明: 系统:ubuntu 20.04 MongoDB:V4.4.6 前言 MongoDB是一种面向文档的数据库管理系统,即非关系型数据库,用C++等语言撰写而成,以解决应用程序开发社区中的大量现实问题。MongoDB由MongoDB Inc.(当时是10gen团队)于2007年10月开发,2009年2月首度推出,现以服务器端公共许可(SSPL)分发。 MongoDB社区版是免费的,包含Windows、Linux和OS X的二进制版本。许多Linux包管理系统曾经包含MongoDB的包,由于许可证变更,MongoDB已经从Debian、Fedora和Red Hat Enterprise Linux发行版中被移除。 本篇博客中ubuntu安装MongoDB的过程参考自MongoDB官网:Install MongoDB Community Edition on Ubuntu — MongoDB Manual,其他派系Linux安装MongoDB请参考:Install MongoDB Community Edition on Linux — MongoDB Manual。 1、导入MongoDB公共 GPG 密钥 用以下命令从https://www.MongoDB.org/static/pgp/server-4.4.asc导入MongoDB公共GPG密钥: wget -qO - https://www.mongodb.org/static/pgp/server-4.4.asc | sudo apt-key add - 出现OK字样表示导入成功。若中途提示gnupg未安装,用以下命令安装: sudo apt-get install gnupg 安装之后尝试重新导入,直至出现OK字样。 2、创建列表文件 在ubuntu上创建列表文件/etc/apt/sources.list.d/mongodb-org-4.4.list,不同版本的ubuntu命令也不同(其实只是命令中的版本号不同): # Ubuntu 20.04 (Focal): echo "deb [ arch=amd64,arm64 ] https://repo.mongodb.org/apt/ubuntu focal/mongodb-org/4.4 multiverse" | sudo tee /etc/apt/sources.list.d/mongodb-org-4.4.list # Ubuntu 18.04 (Bionic) echo "deb [ arch=amd64,arm64 ] https://repo.mongodb.org/apt/ubuntu bionic/mongodb-org/4.4 multiverse" | sudo tee /etc/apt/sources.list.d/mongodb-org-4.4.list # Ubuntu 16.04 (Xenial) echo "deb [ arch=amd64,arm64 ] https://repo.mongodb.org/apt/ubuntu xenial/mongodb-org/4.4 multiverse" | sudo tee /etc/apt/sources.list.d/mongodb-org-4.4.list 若不确定系统版本号,用“lsb_release -a”命令查看,“Codename”一项即是版本号 3、用命令安装MongoDB 3.1 安装最新版本 输入以下命令安装MongoDB,默认安装最新版: # 更新软件源中的所有软件列表: sudo apt update sudo apt-get install -y mongodb-org 3.2 安装指定版本 如果要安装指定版本,必须分别指定每个组件包和版本号,比如: sudo apt-get install -y mongodb-org=4.4 mongodb-org-server=4.4 mongodb-org-shell=4.4 mongodb-org-mongos=4.4 mongodb-org-tools=4.4 如果只安装MongoDB-org = 4.4,并且不包含组件包,那么无论指定了哪个版本,都将安装每个 MongoDB 包的最新版本。 在安装完指定的MongoDB版本后,用apt命令升级软件时仍会升级到新版本的MongoDB。因此为了防止意外升级,可以将软件包固定在当前安装的版本上: echo "mongodb-org hold" | sudo dpkg --set-selections echo "mongodb-org-server hold" | sudo dpkg --set-selections echo "mongodb-org-shell hold" | sudo dpkg --set-selections echo "mongodb-org-mongos hold" | sudo dpkg --set-selections echo "mongodb-org-tools hold" | sudo dpkg --set-selections 4.启动MongoDB 要运行和管理mongod进程,将使用操作系统内置的init系统。Linux的新版本倾向于使用systemd(使用 systemctl 命令) ,而Linux的旧版本倾向于使用System v init(使用service命令)。这就导致不同的init系统操作mongod进程的命令不同,请根据系统的不同来使用。 如果不确定平台使用的是哪个init系统,请运行以下命令: ps --no-headers -o comm 1 然后根据结果选择下面的相应命令: systemd - 选择4.1 systemd (systemctl) 。 init - 选择4.2 System V Init (service)。 4.1 systemed(systemctl): # 启动MongoDB: sudo systemctl start mongod # 并将其加入开机启动项: sudo systemctl enable mongod # 用以下命令验证MongoDB是否启动运行成功: sudo systemctl status mongod # 停止MongoDB: sudo systemctl stop mongod # 重新启动MongoDB: sudo systemctl restart mongod 若启动时,出现错误:“Failed to start mongod.service: Unit mongod.service not found”,则运行以下命令: sudo systemctl daemon-reload 然后再次运行start命令即可: sudo systemctl start mongod 4.2 System V Init(service): # 启动MongoDB: sudo service mongod start # 用以下命令验证MongoDB是否启动运行成功: sudo service mongod status # 停止MongoDB: sudo service mongod stop # 重新启动MongoDB: sudo service mongod restart 验证MongoDB启动成功是这样的: MongoDB启动之后默认运行在27017端口。其配置文件在“/etc/mongod.conf”,运行端口等信息可在配置文件中修改。 5.管理MongoDB数据库 使用Robo 3T来管理MongoDB数据库,Robo 3T下载地址:Robomongo 开启远程连接之前,我们先要建立一个管理员用户,因为MongoDB默认是没有用户的。在控制台输入命令连接数据库: mongo # 如果更改了默认连接端口,则在连接时还需要指定连接端口 mongo -port 端口号 连接到数据库之后使用以下语句来建立一个管理员用户: # 选择连接admin数据库 use admin # 创建一个用户名为“root”,密码为“1234”管理员用户: db.createUser( { user:"root", pwd:"1234", roles:[{role:"root",db:"admin"}] } ) 创建成功的话会有“successfully”字样提示。使用“db.getUsers()”命令可以查询当前所有用户。 默认情况下,MongoDB是不允许远程连接的,所以需要在/etc/mongod.conf配置文件中进行一些配置。编辑配置文件: sudo nano /etc/mongod.conf 这是官网中对于配置文件mongod.conf每一个选项的详细介绍:Configuration File Options — MongoDB Manual。 配置文件中有一项是”net“,下面的”bindIp“一项的值原来是127.0.0.1,表示只能由本机访问MongoDB数据库,为了能远程访问管理数据库,需要将这项的值修改为0.0.0.0 net: port: 27017 - bindIp: 127.0.0.1 + bindIp: 0.0.0.0 同时,此时的数据库任何人使用任何网络都能连接,极度不安全。因此我们需要开启安全授权,同样的,在配置文件/etc/mongod.conf中添加如下内容: security: authorization: "enabled" 修改完之后保存退出,然后重启mongod服务: sudo systemctl restart mongod 然后我们就可以用这个用户登录管理数据库了。 更多MongoDB数据库用户的操作请参考:MongoDB添加用户 - MongoDB教程™ (yiibai.com) 打开Robo 3T客户端,新建一个Connection。输入服务器的ip地址或域名,端口填写默认的27017(或者修改之后的端口)。然后切换Authentication选项卡,在第一行前打上勾,输入框中输入用户名密码,填写完之后点击下面Test按钮,若是测试连接无误,点击Save保存下来,就能连接到数据库了。 附:在更改MongoDB连接端口时遇到的坑 MongoDB端口可以在配置文件/etc/mongod.conf进行更改,更改net选项下port的值即可。更改完需要重启MongoDB服务,下次用软件连接数据库时就要更换成更改后的端口。但是用mongo命令在控制台上登录数据库时,就会报错: 这是因为在用mongo命令是依然默认连接的是27017端口,而不是修改之后的端口,因此使用此命令时需要指定端口进行连接: mongo -port 新端口 6.卸载MongoDB 首先停止mongod进程: # systemed(systemctl): sudo systemctl stop mongod # System V Init(service): sudo service mongod stop 删除以前安装的任何 MongoDB 包: sudo apt-get purge mongodb-org* 删除 MongoDB 数据库和日志文件: sudo rm -r /var/log/mongodbsudo rm -r /var/lib/mongodb
-
【踩坑实录】mybatis项目报错:...IncompleteElementException: Could not find parameter map... 环境说明: 系统:Win10专业版 mysql 5.7 问题再现 mybatis进行数据库查询操作时,报错信息如下: org.apache.ibatis.builder.IncompleteElementException: Could not find parameter map com.langp.mapper.CollegeMapper.int 错误原因 Mapper方法中的参数类型是int,应该是用parameterType属性,而不是用parameterMap属性 解决方法 将parmeterMap属性改成parameterType属性即可
-
【踩坑实录】mybatis项目报错:org.junit ... ParameterResolutionException No ParameterResolver registered for parameter ... in method ... 环境说明: 系统:Win10专业版 mysql 5.7 问题再现 往数据库在进行插入操作时,报错信息如下: org.junit.jupiter.api.extension.ParameterResolutionException No ParameterResolver registered for parameter [com.langp.entity.College arg0] in method [public void com.langp.mapper.CollegeMapperTest.insert(com.langp.entity.College)]. 错误原因 进行单元测试的时候,单元测试方法中有参数 解决方法 将单元测试方法中相应的参数移除即可
-
Maven项目中的MyBatis配置 目录: 一、简介 二、创建项目 2.1、导入 Maven 依赖 2.2、创建 mybatis 核心配置文件 3.3、编写工具类 3.4、编写代码 实体类 Dao 接口 UserMapper 接口实现 UserMapper.xml 3.5、测试 三、问题 1、找不到 mapper.xml 文件 2、SSL 连接问题 环境说明: IDE:IDEA 2020.03 Java:jdk 1.8 MyBatis版本:3.5.3 mysql:5.5 mysql-connector-java:5.1.47 Junit:5.7.0 官方文档: mybatis – MyBatis 3 | 简介 Github 地址: GitHub - mybatis/mybatis-3: MyBatis SQL mapper framework for Java Maven 仓库地址: Maven Repository: org.mybatis » mybatis (mvnrepository.com) 一、简介 MyBatis 是一款优秀的持久层框架 支持自定义 SQL、存储过程以及高级映射。 MyBatis 免除了几乎所有的 JDBC 代码以及设置参数和获取结果集的工作。 MyBatis 可以通过简单的 XML 或注解来配置和映射原始类型、接口和 Java POJO(Plain Old Java Objects,普通老式 Java 对象)为数据库中的记录。 MyBatis 本是 apache 的一个开源项目 iBatis,2010 年这个项目由 apache 迁移到了 google code,并且改名为 MyBatis。 2013 年 11 月迁移到 Github。 二、创建项目 准备数据库,设置字符集与排序规则为 utf-8,否则无法正常插入中文字符。 然后执行以下 SQL 语句: -- 创建表 CREATE TABLE user(id INT NOT NULL AUTO_INCREMENT primary key,name char(20),updateTime datetime); -- 插入两条数据 INSERT INTO user(name,updateTime) value("张三",sysdate()); INSERT INTO user(name,updateTime) value("李四",sysdate()); 并且在 idea 中建好一个 Maven 项目。 2.1、导入 Maven 依赖 项目根目录下的 pom.xml 文件配置 Maven 依赖,在这个配置文件中加入以下依赖的坐标: <dependencies> <!--Mybatis--> <!-- https://mvnrepository.com/artifact/org.mybatis/mybatis --> <dependency> <groupId>org.mybatis</groupId> <artifactId>mybatis</artifactId> <version>3.5.3</version> </dependency> <!--mysql驱动--> <!-- https://mvnrepository.com/artifact/mysql/mysql-connector-java --> <dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> <version>5.1.47</version> </dependency> <!--Junit--> <!-- https://mvnrepository.com/artifact/org.junit.jupiter/junit-jupiter-api --> <dependency> <groupId>org.junit.jupiter</groupId> <artifactId>junit-jupiter-api</artifactId> <version>5.7.0</version> <scope>test</scope> </dependency> </dependencies> 2.2、创建 mybatis 核心配置文件 文件名:mybatis-config / mybatis-cfg,或其他 文件模板及说明:mybatis – MyBatis 3 | 入门 <?xml version="1.0" encoding="UTF-8" ?> <!DOCTYPE configuration PUBLIC "-//mybatis.org//DTD Config 3.0//EN" "http://mybatis.org/dtd/mybatis-3-config.dtd"> <configuration> <settings> <!-- 打印sql日志 --> <setting name="logImpl" value="STDOUT_LOGGING"/> </settings> <environments default="development"> <environment id="development"> <transactionManager type="JDBC"/> <dataSource type="POOLED"> <!-- MySQL8.0以下的驱动名叫com.mysql.jdbc.Driver MySQL8.0以上的驱动名是com.mysql.cj.jdbc.Driver --> <property name="driver" value="${driver}"/> <property name="url" value="${url}"/> <property name="username" value="${username}"/> <property name="password" value="${password}"/> </dataSource> </environment> </environments> <!-- 每一个mapper.xml配置文件都需要在mybaits核心文件中注册 --> <mappers> <!-- 使用文件路径的方式配置 --> <!-- <mapper resource="com/wlplove/dao/AtlasMapper.xml"/> --> <!-- 也可以使用类的方式进行配置 --> <mapper class="com.wlplove.dao.AtlasMapper"/> </mappers> </configuration> 其中,在这个配置文件的 <dataSource> 标签中定义了数据库连接信息,这里将信息写成了固定的死值。还有一种更灵活的方式就是从配置文件中读取信息,在 resources 目录下再新建一个数据库配置文件 jdbc.properties,里面写入数据库信息: # MySQL8.0以下的驱动名叫com.mysql.jdbc.Driver MySQL8.0以上的驱动名是com.mysql.cj.jdbc.Driver driver=com.mysql.cj.jdbc.Driver url=jdbc:mysql://localhost:3306/pic?useSSL=false&useUnicode=true&characterEncoding=UTF-8 username=root password=root # 或者也可以配置成以下形式: #driver:com.mysql.jdbc.Driver #url:jdbc:mysql://localhost:3306/mybatis?useSSL=false&setUnicode=true&characterEncoding=utf8 #username:root #password:root 修改配置文件中的数据库信息部分为引用外部配置: <!-- 配置文件的路径 --> <properties resource="jdbc-config.properties"/> <dataSource type="POOLED"> <!-- MySQL8.0以下的驱动名叫com.mysql.jdbc.Driver MySQL8.0以上的驱动名是com.mysql.cj.jdbc.Driver --> <property name="driver" value="${driver}"/> <!-- 使用属性占位符 ${} 读取 property 文件中的属性 --> <property name="url" value="${url}"/> <property name="username" value="${username}"/> <property name="password" value="${password}"/> </dataSource> 3.3、编写工具类 将加载 SqlSession 的过程写成一个工具类,方便调用: public class MyBatisUtil { /** * 根据 XML 配置文件初始化出 SqlSessionFactory,并获取到 SqlSession 对象 * @return sqlSession */ public static SqlSession getSqlSession() { SqlSession sqlSession = null; try { String xmlFileResource = "mybatis-config.xml"; InputStream inputStream = Resources.getResourceAsStream(xmlFileResource); SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(inputStream); sqlSession = sqlSessionFactory.openSession(); } catch (Exception e) { e.printStackTrace(); } return sqlSession; } } 3.4、编写代码 实体类 即业务中涉及到的类,并且包括构造方法、getter 方法、setter 方法以及 toString() 方法 public class User { private int id; private String name; private Date updateTime; // 构造方法、set方法、get方法、toString方法略.... } Dao 接口 UserMapper public interface UserMapper { List<User> getUserList(); } 接口实现 UserMapper.xml 原来的 UserDaoImpl 转换为一个接口的 Mapper 映射文件: <?xml version="1.0" encoding="UTF-8" ?> <!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd"> <!-- namespace绑定一个Dao/mapper接口 --> <mapper namespace="com.wlplove.dao.UserMapper"> <!-- 查询语句 --> <!-- 注意其中的id,和resultType返回类型的名称 --> <select id="getUserList" resultType="com.wlplove.pojo.User"> SELECT * FROM mybatis.user; </select> </mapper> 定义好 Mybatis 的这个 Mapper 映射文件之后,需要在 Mybatis 的配置文件中注册一下才能正常调用: <!-- 每一个mapper.xml配置文件都需要在Mybaits核心文件中注册,有这么两种方式注册: --> <mappers> <!-- 使用文件路径的方式 --> <!-- <mapper resource="com/wlplove/dao/AtlasMapper.xml"/> --> <!-- 也可以使用类的方式 --> <mapper class="com.wlplove.dao.AtlasMapper"/> </mappers> 3.5、测试 只要在前面导入了 Junit 的依赖之后,就可以写一个单元测试方法调用写好的接口,单元测试方法没有返回值,没有参数,可以像 main 方法一样直接执行。 class UserMapperTest { // 每一个单元测试方法前面加入 @Test 注解 @Test void getUserList() { // 获取sqlSession对象 SqlSession sqlSession = MybatisUtil.getSqlSession(); // 执行sql UserMapper mapper = sqlSession.getMapper(UserMapper.class); List<User> userList = mapper.getUserList(); for (User user : userList) { System.out.println(user); } // 关闭sqlSession sqlSession.close(); } } 三、问题 1、找不到 mapper.xml 文件 报错信息:Error parsing SQL Mapper Configuration. Cause: java.io.IOException: Could not find resource com/wlplove/dao/UserMapper.xml 原因是 Maven 在打包的时候,默认打包 src/main/java 下的 class 文件与 src/main/resources 下的配置文件,没有将该路径下的 mapper 配置文件打包进来,导致运行时候找不到 mapper 文件而报错。 解决方法:手动指定资源文件的位置,参考:mybatis:Error parsing SQL Mapper Configuration. Cause: java.io.IOException: Could not find resource_在路上s的博客-CSDN博客 修改 pom.xml 文件,在里面加入以下内容,然后更新 Maven 配置即可: <build> <!-- **.xml写在src找不到问题解决方案 --> <resources> <resource> <!-- directory:指定资源文件的位置 --> <directory>src/main/java</directory> <includes> <!-- “**” 表示任意级目录 “*”表示任意任意文件 --> <!-- mvn resources:resources :对资源做出处理,先于compile阶段 --> <include>**/*.properties</include> <include>**/*.xml</include> </includes> <!-- filtering:开启过滤,用指定的参数替换directory下的文件中的参数(eg. ${name}) --> <filtering>false</filtering> </resource> <resource> <directory>src/main/resources</directory> </resource> </resources> </build> 2、SSL 连接问题 报错信息: WARN: Establishing SSL connection without server's identity verification is not recommended. According to MySQL 5.5.45+, 5.6.26+ and 5.7.6+ requirements SSL connection must be established by default if explicit option isn't set. For compliance with existing applications not using SSL the verifyServerCertificate property is set to 'false'. You need either to explicitly disable SSL by setting useSSL=false, or set useSSL=true and provide truststore for server certificate verification. 翻译过来就是: 警告:不建议在没有服务器身份验证的情况下建立SSL连接。根据MySQL 5.5.45+、5.6.26+和5.7.6+的要求,如果没有设置显式选项,则默认情况下必须建立SSL连接。为了符合不使用SSL的现有应用程序,verifyServerCertificate属性设置为“false”。您需要通过设置useSSL=false来显式禁用SSL,或者设置useSSL=true并为服务器证书验证提供信任存储。 在数据库的连接参数中添加不使用 SSL 连接的参数 useSSL=false 即可解决: <property name="url" value="jdbc:mysql://localhost:3306/practice?setUnicode=true&characterEncoding=utf8&useSSL=false"/> 参考: 史上最详细mybatis与spring整合教程-腾讯云开发者社区-腾讯云 (tencent.com)
-
【踩坑实录】Nginx重新加载时出现警告:nginx: [warn] conflicting server name "www.langp.wang" on 0.0.0.0:80, ignored 环境说明: 系统:ubuntu 20.04 nginx:1.18.0 问题再现: 修改nginx配置文件后,在执行nginx -s reload命令重新载入nginx服务时出现错误: nginx: [warn] conflicting server name "www.langp.wang" on 0.0.0.0:80, ignored nginx: [warn] conflicting server name "www.langp.wang" on 0.0.0.0:443, ignored 可以看到提示“conflicting server name”,即“服务器名称冲突”,而且是在“80”和“443”两个端口上都有的。 错误原因: 在nginx的每一个server配置中都有一个“server_name”配置项,nginx是用“server_name”来确定域名与对应网站的关联的。而当nginx中出现了两个相同的“server_name”时,重新加载时nginx服务时就会出现冲突了,就会产生警告信息。由于提示信息只是“warn”级别的,所以网站还是能正常访问到的,可是这个警告信息还是让人觉得很不爽。 解决方法: 经过排查,发现是在配置文件的目录下(/etc/nginx/sites-enabled)多出来了一个与原来的配置文件名称相同,但是名称后缀为“.save”的文件。这个文件中的所有信息与原来文件的所有内容相同,所以就出现了两个相同的”server_name“。 把这个文件删除掉之后,再次执行命令nginx -s reload就没有警告信息了。 至于这个文件的来源,个人猜测可能是由于用nano编辑器编辑文件时产生的缓存或者是nano编辑器被强制退出时保存的信息。
-
【踩坑实录】mybatis项目报错:“Caused by: .....Exception: 1 字节的 UTF-8 序列的字节 1 无效” 环境说明: 系统:win10 专业版 开发环境:IDEA JDK版本:1.8 mysql:5.5 mybatis:3.5.3 Junit:5.7.0 问题再现: 运行mybatis项目时,控制台出现报错信息: Caused by: com.sun.org.apache.xerces.internal.impl.io.MalformedByteSequenceException: 1 字节的 UTF-8 序列的字节 1 无效 错误原因: 归根结底是编码的原因,xml文件开头的文档编码设置为了UTF-8: 而由于项目本身的默认编码是GBK,因此xml文件保存时的编码是GBK,声明的xml文档编码与实际编码不一致,就出现了问题 解决方法: 更改项目编码即可。 在IDEA界面打开setting(点击File->setting或者快捷键Ctrl+Alt+S),依次选择Editor->File encodings,将Project Encoding的值从GBK更改为UTF-8。 再次运行,问题消失。
-
【踩坑实录】Maven项目报错:java.lang.ExceptionInInitializerError 环境说明: 系统:win10 专业版 开发环境:IDEA JDK版本:1.8 mysql:5.5 mybatis:3.5.3 Junit:5.7.0 问题再现: Maven项目运行时报错,控制台报错信息如下: java.lang.ExceptionInInitializerError at com.langp.dao.UserMapperTest.getUserList(UserMapperTest.java:26) at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) at java.lang.reflect.Method.invoke(Method.java:498) ······ Caused by: org.apache.ibatis.exceptions.PersistenceException: ### Error building SqlSession. ### The error may exist in com/langp/dao/UserMapper.xml Process finished with exit code -1 错误原因: 程序在编译过程中找不到对应的配置文件就会报错,但是对应的配置文件却是的的确确存在于项目中的,可是在生成的测试结果target对应目录下找不到对应配置文件,这是因为Maven项目中默认资源配置目录是src/main/resource,而实际有些配置文件会放在src/main/java目录下,就会导致项目编译时导出不了这些配置文件。所以我们需要手动配置资源过滤,使src/main/java的”.properties“文件和”.xml“文件可被导出到测试结果的target文件夹中。 解决方法: 最简单的方式就是将对应的Mapper.xml文件复制到生成测试结果的target文件夹下对应的目录中,但是只要在Maven中执行一次clear操作,target文件夹就被清除了,下次编译时还要重新复制过去。所以还有种更简单的方法: 在Maven项目的配置文件”pom.xml“中添加如下过滤配置信息: <!-- 在build中配置resources,来防止资源导出失败的问题 --> <build> <resources> <resource> <directory>src/main/resources</directory> <includes> <include>**/*.properties</include> <include>**/*.xml</include> </includes> <filtering>true</filtering> </resource> <resource> <directory>src/main/java</directory> <includes> <include>**/*.properties</include> <include>**/*.xml</include> </includes> <filtering>true</filtering> </resource> </resources> </build> 然后,在IDEA中右键依次选择”Maven“->”Reload project“,重新载入依次Maven配置信息即可。











![【踩坑实录】Nginx重新加载时出现警告:nginx: [warn] conflicting server name "www.langp.wang" on 0.0.0.0:80, ignored](https://image.wlplove.com/%E5%AD%A6%E4%B9%A0%E7%82%B9%E6%BB%B4/%E8%B8%A9%E5%9D%91%E5%AE%9E%E5%BD%95/%E3%80%90%E8%B8%A9%E5%9D%91%E5%AE%9E%E5%BD%95%E3%80%91Nginx%E6%9C%8D%E5%8A%A1%E9%87%8D%E6%96%B0%E8%BD%BD%E5%85%A5%E6%97%B6%E5%87%BA%E7%8E%B0%E8%AD%A6%E5%91%8A/img/01.png)

