

目录:
运行环境:
Win11 专业版、ComfyUI 0.12.3
Python 版本 : 3.12.12
PyTorch 版本: 2.9.0
CUDA 版本 : 12.8
显卡:RTX 2080Ti 22G
整理一下我自己折腾 ComfyUI 的过程中涉及到图片反推、动作迁移、动作编辑等方面的一点东西。
全部工作流:My-ComfyUI-Workfolws
一、图片反推提示词
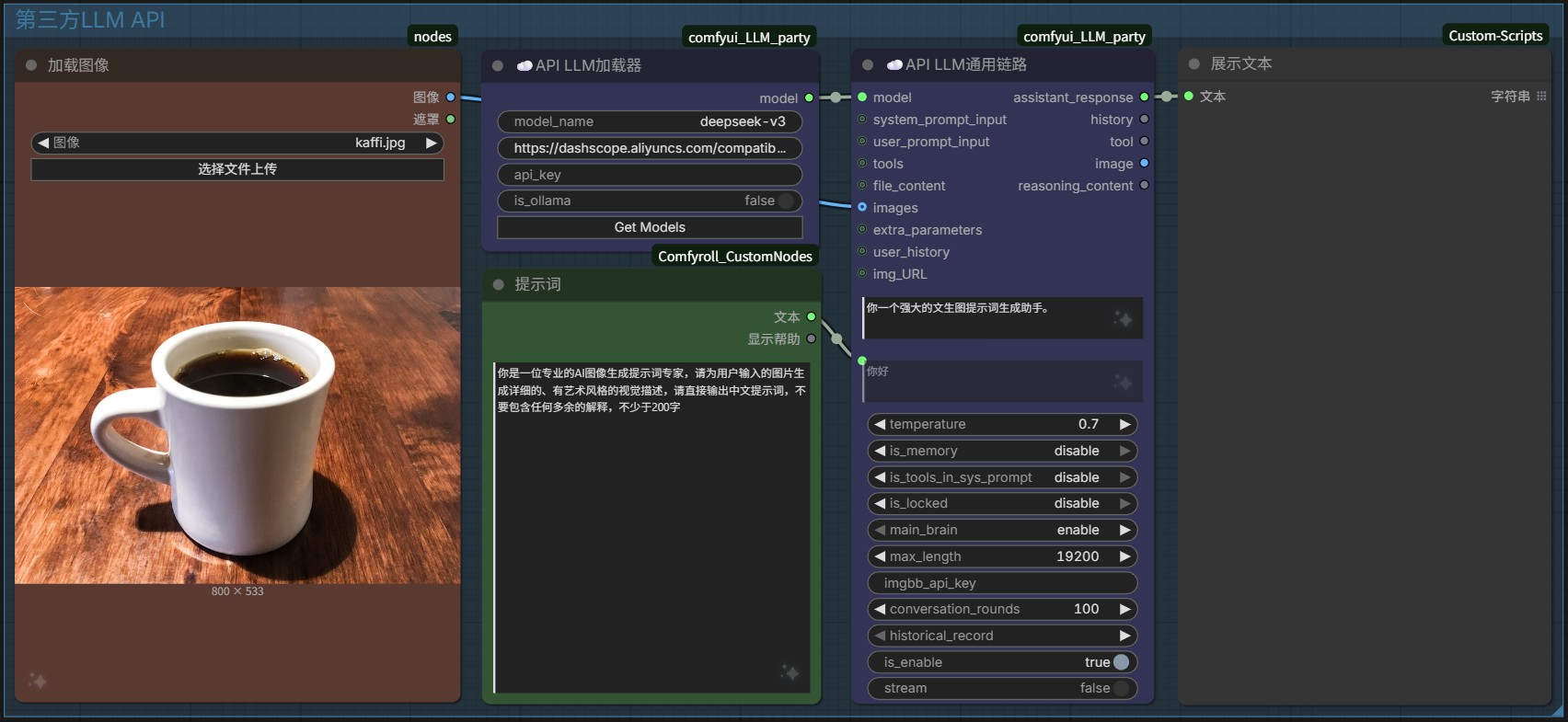
1.1、调用API
插件:heshengtao/comfyui_LLM_party
通过调用第三方模型 API 来反推图片提示词,但是对于 NSFW 图片就不太适用,会被拦截。
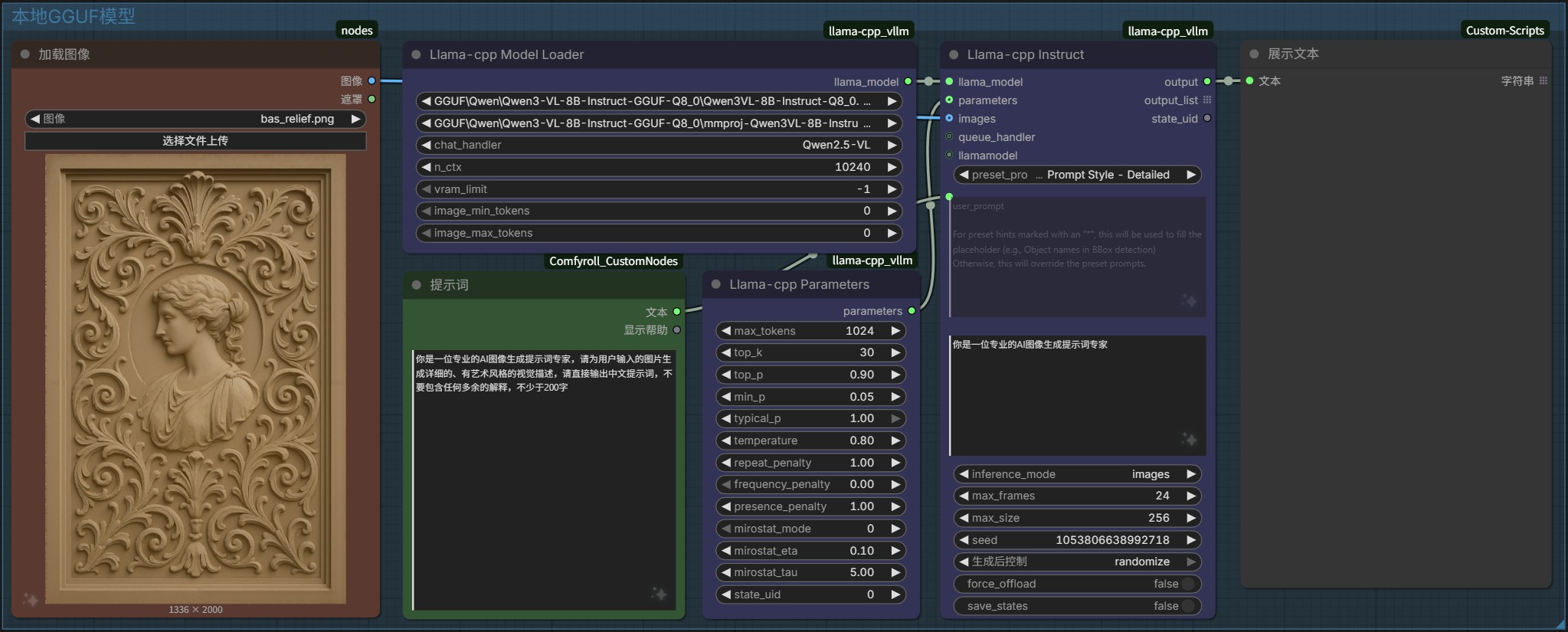
1.2、运行本地LLM
插件:lihaoyun6/ComfyUI-llama-cpp_vlm
使用本地运行 GGUF 模型来反推图片提示词,不限模型,虽然本地模型能力方面肯定不如通过第三方满血模型,但是还算够用,而且没什么限制。
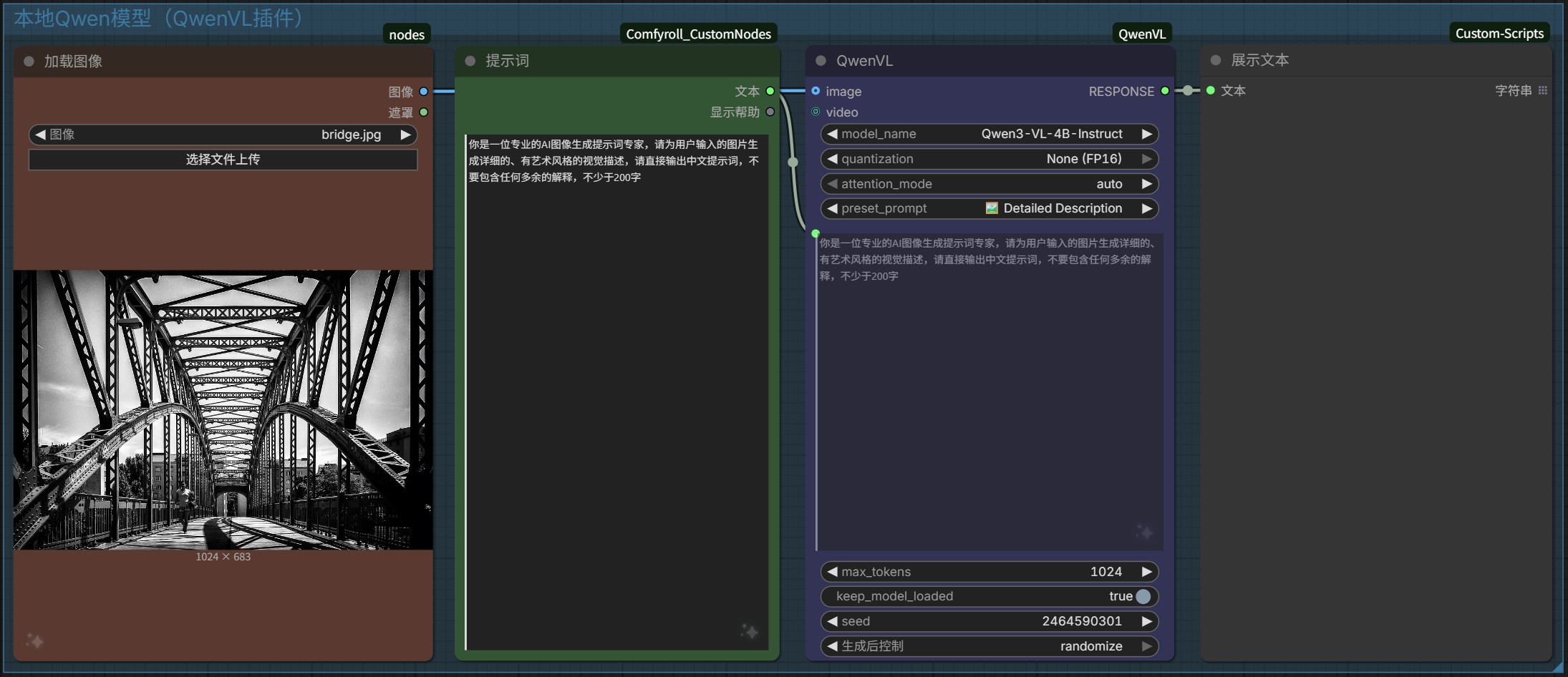
1.3、本地Qwen模型
只能用 Qwen 系列模型,可选的模型比较多,如果本地不存在模型文件,运行时会自动从魔搭下载,但是下载的模型文件没法被其他插件使用,所以我在 ComfyUI 中使用本地大模型还是会选择上面的方式,毕竟本地硬盘空间宝贵,GGUF 模型文件还能在 LM Studio 中使用。
二、扩写/优化提示词
整体工作流与上面反推图片提示词的工作流基本相同,只不过不用传图片。就不再赘述了。
三、动作/多角度
3.1、动作迁移:
迁移图片中的人物动作,虽然做不到百分百迁移,整体效果还凑活
插件:Fannovel16/comfyui_controlnet_aux
工作流参考:
- DWPreProcessor:[Z_Image_Turbo - DWPreprocessor姿态迁移修改](https://gitee.com/longalone/My-ComfyUI-Workfolws/blob/master/生图/Z_Image_Turbo - DWPreprocessor姿态迁移修改.json)
- OpenPose:[Z_Image_Turbo - OpenPose姿态迁移修改](https://gitee.com/longalone/My-ComfyUI-Workfolws/blob/master/生图/Z_Image_Turbo - OpenPose姿态迁移修改.json)
3.2、动作编辑
识别图片人物动作的骨骼框架,通过 OpenPose-Editor 插件编辑,整体效果感觉还不错
插件:
工作流参考:
- [Qwen_Image_Edit - 人物姿势编辑](https://gitee.com/longalone/My-ComfyUI-Workfolws/blob/master/图像编辑/Qwen_Image_Edit - 人物姿势编辑.json)
- [Qwen_Image_Edit - 提示词编辑姿势+角度 ](https://gitee.com/longalone/My-ComfyUI-Workfolws/blob/master/图像编辑/Qwen_Image_Edit - 提示词编辑姿势%2B角度.json)
3.3、多角度
生成图片的多角度分镜图,效果不稳定,有时还不错,有时又不太行,需要抽卡
插件:
工作流参考:
- [Qwen_Image_Edit - 多角度出图](https://gitee.com/longalone/My-ComfyUI-Workfolws/blob/master/图像编辑/Qwen_Image_Edit - 多角度出图.json)
- [Qwen_Image_Edit - 提示词编辑姿势+角度](https://gitee.com/longalone/My-ComfyUI-Workfolws/blob/master/图像编辑/Qwen_Image_Edit - 提示词编辑姿势%2B角度.json)
四、Latent 解码
众所周知,云端的 ComfyUI 环境(比如 RunningHub)一般都会拦截 NSFW 图片/视频,由于拦截过程是在工作流完成跑完才进行的,所以也很好规避拦截。既然只针对 VAE 解码出来的图片/视频进行拦截,那不在云端解码就好了嘛,具体实现方法就是把云端工作流中 K 采样器生成好的 Latent 文件输出到“保存Latent”节点,工作流跑完之后手动把 Latent 文件下载放到本地的 output 目录,最后使用“加载Latent”节点加载这个 Latent 文件,使用对应的 VAE 模型解码成图片/视频就可以了。
每个生图、生视频的模型对应的 VAE 模型都不一定相同,参考原工作流或者官方模型仓库文件,如果实在搞不明白的话问 AI 也行。
本地解码工作流参考:Latent本地解码
如果嫌手动下载 Latent 文件麻烦,也有另一种方式,就是在本地调用 RunningHub 的工作流 API,从 API 的输出中直接获取到 Lantent 文件,然后进行 VAE 解码。
虽然不用手动下载 Latent 文件,但是需要修改云端的工作流使其输出 Latent 文件,而且本地调用工作流 API 时参数一多上送起来也比较麻烦,不过如果批量生图/生视频还是比手动下载 Latent 要好点。
RunningHun API 插件:HM-RunningHub/ComfyUI_RH_APICall
调用 API 本地解码工作流参考:[RunningHub API解码Latent](https://gitee.com/longalone/My-ComfyUI-Workfolws/blob/master/工具/RunningHub API解码Latent.json)
五、其他好用的提示词插件
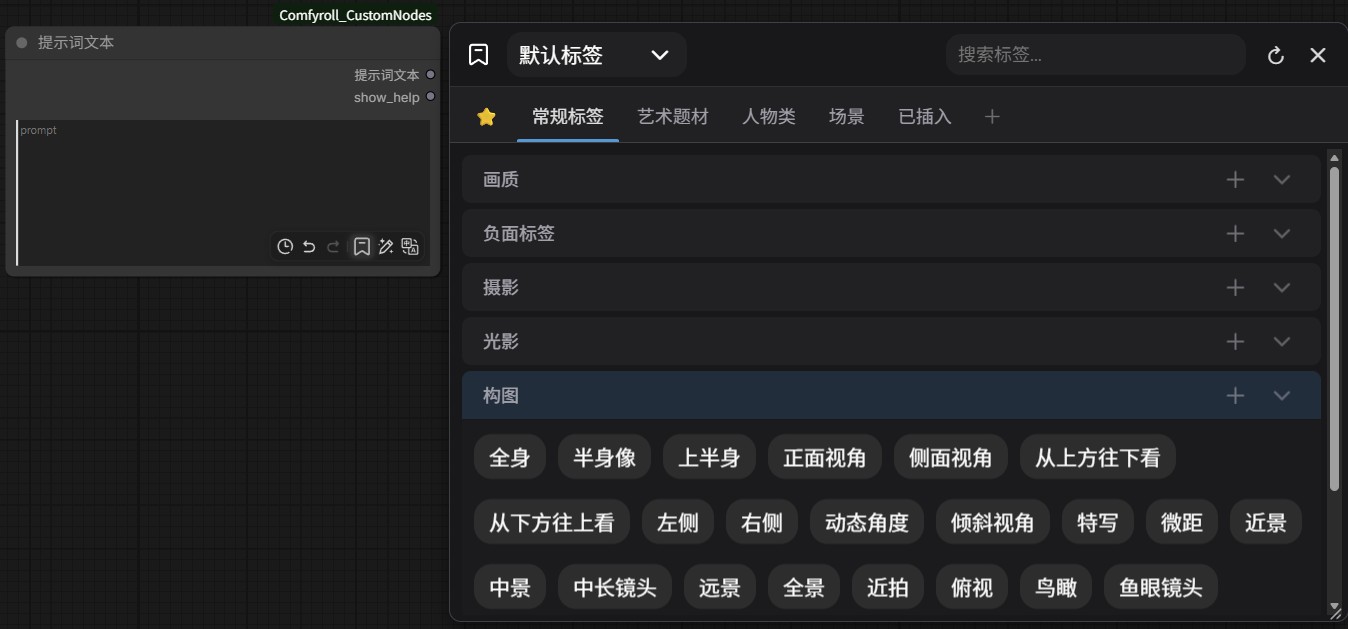
提示词小助手
地址:yawiii/ComfyUI-Prompt-Assistant
很好用的提示词插件,可以说是必装的插件。
可以一键调用智谱、硅基流动、gemini、本地ollama、百度等大语言模型服务,实现提示词一键翻译、润色扩写、图片反推。支持提示词预设实现插入、历史提示词查找等功能。
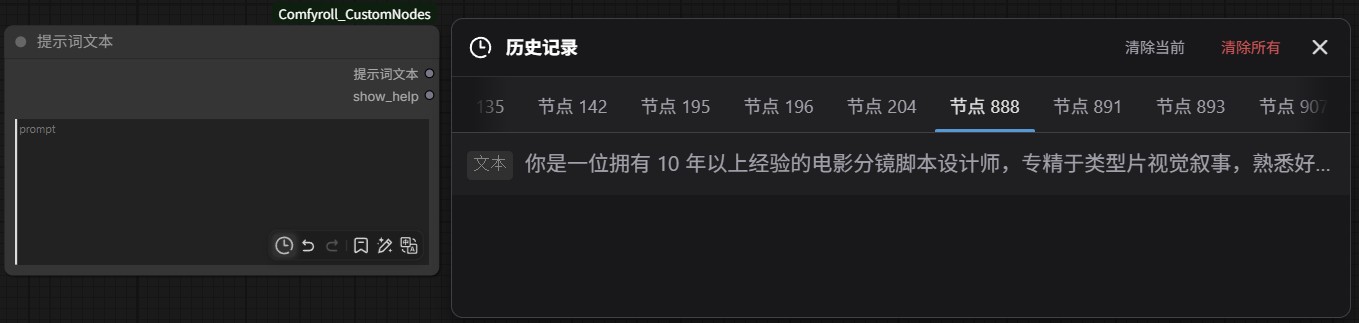
提示词一键插入:
提示词历史记录:
提示词编辑节点
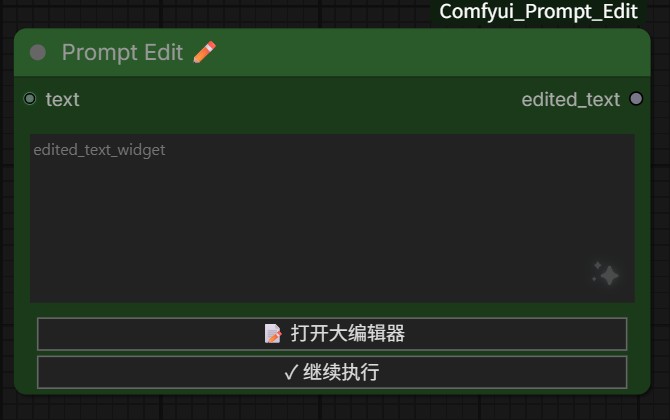
地址:xuchenxu168/Comfyui_Prompt_Edit
提供一个 “Prompt Edit” 节点,工作流执行经过这个节点时会暂停,允许我们编辑文本提示词,然后继续执行。
提示词选择器
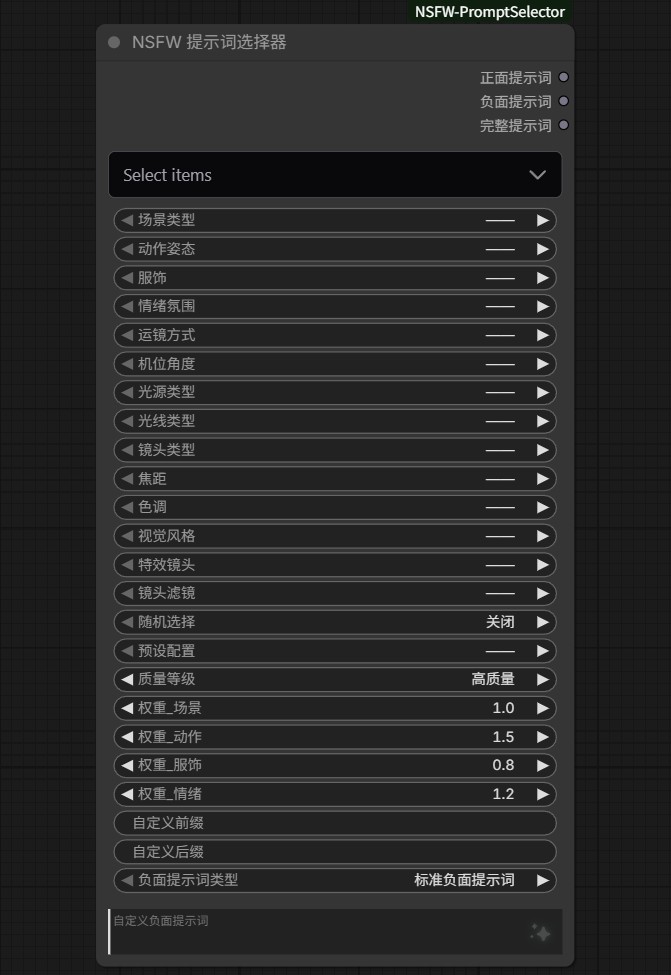
地址:weekii8282/ComfyUI-NSFW-PromptSelector
可生成 NSFW 内容的提示词,不多说,懂得都懂。




评论 (0)